The Information Frontier
A reductionist view of machine learning as a perpetual data refinery, and a re-calibration of its primitives. Why the information frontier is perpetually expanding, what physics says about ever collapsing it, and what it implies for the learning systems we build and study.

TL;DR — Machine learning can be read as a perpetual data refinery: we take data in one state, apply operations, and get a new state out. This essay sketches the "information frontier" — the perpetually expanding boundary between what can be sensed and what has been turned into digital bits — using four operators (evolution, measurement, computation, actuation). Physics (the Lloyd ceiling, the Landauer floor) suggests the frontier is structural and won't collapse any time soon. A small in-the-wild test with the Brickroad team (@TryBrickroad) across frontier models (Opus 4.7, Gemini 3.1 Pro, Codex 5.3) shows the binding constraint today is access, not the model — which motivates access-infrastructure work, including open-source efforts at MLCommons like Croissant and the Agent Data Protocol.
The last couple of years in machine learning have felt like a lot, in both the good and the exhausting sense. Wherever you sit on hype, capacity ceilings, or the end of human anything, it feels like re-calibration is in the air.
My reductionist view of ML has long been that of a perpetual data refinery: we take data arrays in one state, apply operations, and get a new state of data. Inputs, weights, labels in; outputs, fine-tuned weights, evaluations out.
But the warm, familiar primitives we settled on during the, dare I say, "classic deep learning era" now sometimes feel both too coarse and too granular at the same time to express what I am interested in and observing in learning systems. Machine learning escaped the repos and notebooks. It now lives at the fingertips of many million users.
So I've been after my own personal re-calibration to express the questions and work I have become interested in over the last few years. The top-level domain for all this is working-titled the information frontier. Below I sketch some of my intuitions around the concept, why I think the frontier is perpetually expanding, and what I think this implies for the learning systems we are working on and studying.
There is some more pedantic, scientific work forthcoming; however, I also include some backlinks to inspirations and interesting related work in this digest.
Definitions
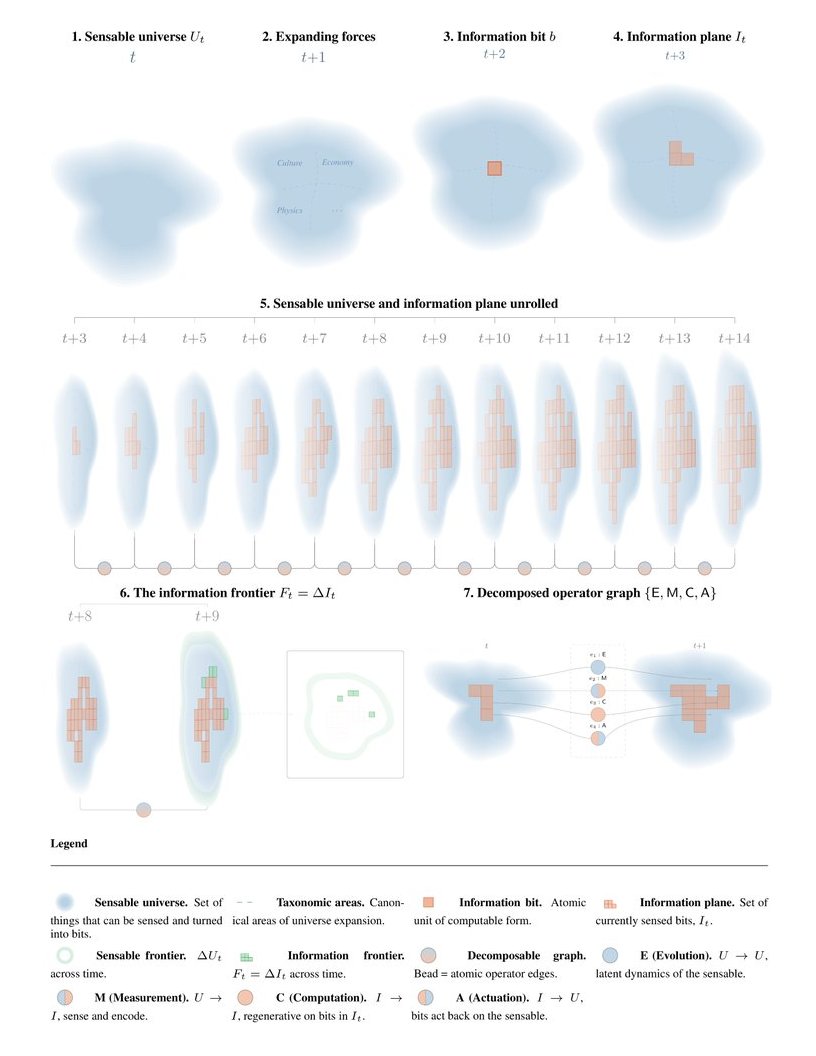
For what follows I included my visual intuition in Figure 1 as a crutch that may help the reader. Let us start by splitting things into two. There is a sensable universe at any given time t, and we define it as the set of things that can be sensed given the instrumentation we have. A telescope does not make stars exist; it makes them sensable.

Whatever fraction of the sensable universe has been turned into digital form I'll call the information plane, with the digital bit as the atomic unit. My intuition here for the use of the word information is following its Latin etymology informare, give form to. So I consider information things that have been given form to, ready for digital computation. The same content can sit in the plane many times. Every copy of the MoM-z14 picture on the internet contributes, so the plane is a multiset rather than a set.
Four operators drive the state changes of the sensable universe and the information plane over time, and for simplicity we group them as: evolution (operations that drive change in the sensable universe), measurement (operations by which the sensable universe gets transformed into digital bits), computation (bits producing more bits, so these operations are regenerative with respect to the information plane), and actuation (operations by which digital bits act back on the sensable universe). In shorthand I use:
Fₜ := ΔIₜ = Iₜ₊₁ ∖ Iₜ
As can be gleaned from the etymology — I found myself rereading [cs48, nw48, sl02] in separating these concepts — I'll go into some more detail below. Equipped with these distinctions we can run some back-of-envelope thought experiments and tests. Below I first mainly want to focus on the relation between Uₜ and Iₜ globally, as well as how Iₜ materializes from a more local perspective, e.g. from an agent's view.
Why the frontier could be ever-structural
One core question I have been interested in is the following: is the information frontier a structural artifact? Or could we possibly get to a point where we collapse the entire sensable universe into the information plane at any given moment in time — having them move in perfect synchrony for computational bliss, if you will?
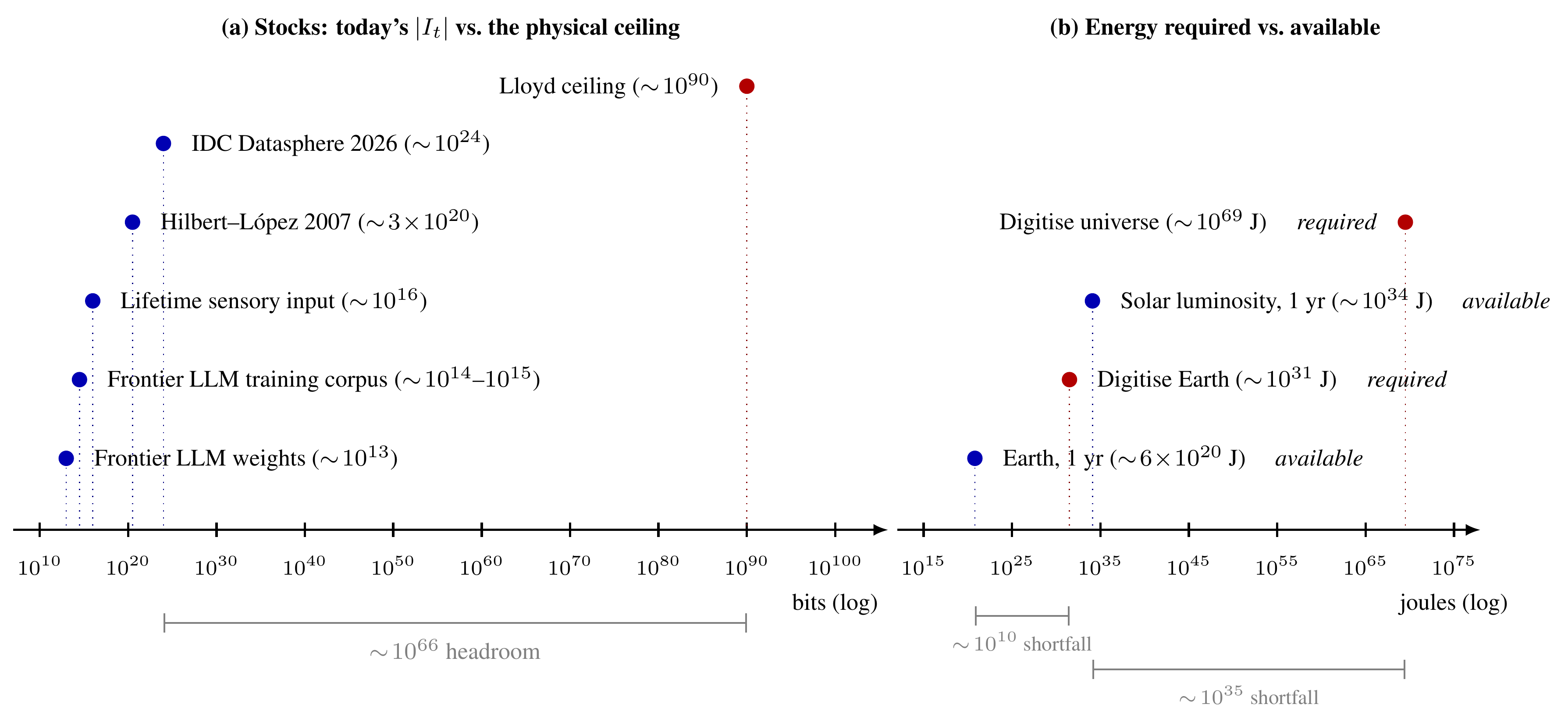
At the moment it looks to me like physics would get in the way. The cosmological ceilings (Figure 3) we'd need to reach for frontier collapse seem out of reach.
Take storage first. How many bits any bounded region of space can hold is capped by its mass and radius. Bekenstein worked this out in the early 1980s [jb81]. Lloyd later plugged the entire observable universe into Bekenstein's formula and read off an absolute cosmic encoding ceiling [sl00, sl02]. Today's global digital store sits roughly 66 orders of magnitude below that ceiling, which is the headroom on storage (Figure 3, left). To illustrate, a 2026 frontier model is built from roughly the same number of bits of text as a single human takes in across a lifetime of visual input [ad24, tn98, jz25]. That's napkin math that ignores compression, encoding overhead, cross-modal redundancy, and a lot else, but the two numbers land within an order of magnitude of each other.
Production has been rising on top of that, with digital data growth at roughly an order of magnitude per decade and no visible flattening [mh11, dr18, jr24]. Hilbert [mh11] and International Data Corporation (IDC) reports [dr18, jr24] measure slightly different things and neither is perfect: Hilbert collapses duplicates and counts compressed bits, IDC counts copies, so they sit an order of magnitude apart on the same year, but the trend points in similar directions.
Another binding ceiling on the absorption capacity of the sensable universe into the information plane is energy. Landauer estimated that erasing a single bit costs at least a particular thermodynamic floor, around kT ln 2 joules at room temperature [rl61]. Across an entire Earth-scale digitisation we'd need roughly ten orders of magnitude more energy than the Earth gets from the Sun in a year (Figure 3, right). The asterisk on Landauer's estimate is that it only applies to logically irreversible operations [hv26]. As an example, for LLM-based computation systems the per-token cost of frontier inference has been collapsing at roughly two orders of magnitude per year [sa25, ep25], driven by smaller process nodes, voltage scaling, quantization, sparsity, model distillation, and other hardware specialization, all still squarely in the irreversible paradigm. How far the energy ceiling can actually drop, and whether reversible computing ever leaves the lab, remains to be seen.
Surfing the frontier by way of harness?
Now, the way that most production-grade LLM stacks today cope with the perpetual information frontier is through duct taping. A pretrained model gets retrieval, tool use, code execution, scratchpads, planners, judges, and persistent memory chained around it [aa26].
There are orthogonal proposals, ones that look for answers in silver-bullet algorithms that can stand the stresses of the perpetual information frontier expansion, including novel ideas for learning algorithms [yl22, gh22] and complementing testing scenarios [fc19, hk20, ta24].
Already today, these fault lines become more and more blurry, in my opinion. Harness-patches that make models more useful already get absorbed and collapsed into new model releases. And models get shipped as increasingly composite systems that go way beyond string-in string-out. Harnesses become part of the optimisation surface [yl26] itself. So personally I get confused by some of the structure vs. liquid wars we have seen pop up [ml26, kl26, th26]. It looks like duct tape is just part of the hill climb and we settle on representations for them in the stack that are efficient. There may be a sibling to Sutton's bitter lesson [rs19] in sight:
How you construct the computational state-transition graph from the digital bits matters less than that you can construct one at all.
A small test in the wild
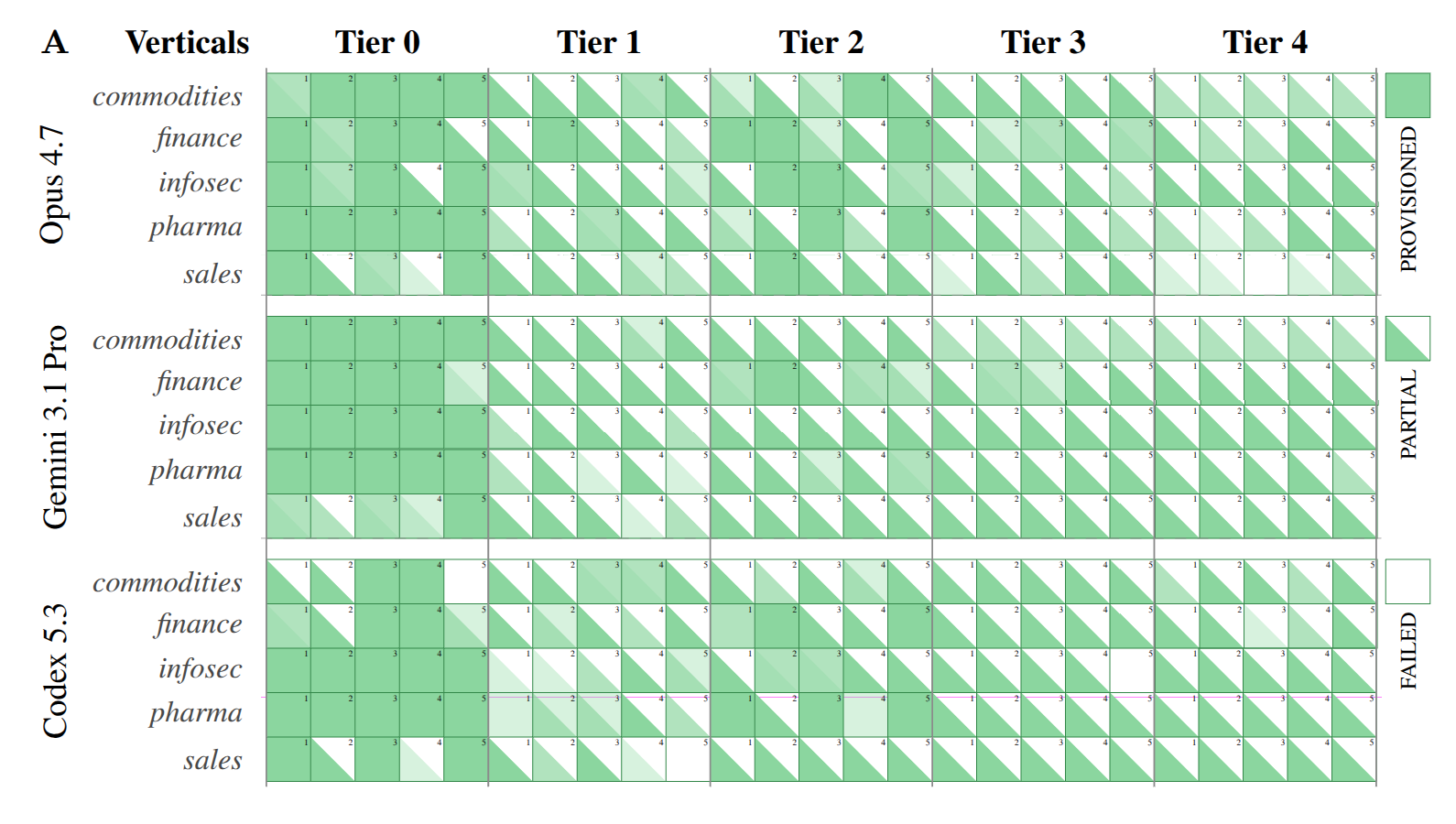
We can get an intuition for the information frontier in practice by probing models. We started these little "information frontier speedruns" with our team @TryBrickroad on a slate of popular models (Opus 4.7, Gemini 3.1 Pro, Codex 5.3). The rules are simple: point the agent against a roster of sources across five verticals in economically valuable domains (commodities, finance, security, pharma, sales) and see how far the agent can get to expand its own frontier. Rinse and repeat a couple of times to get some sense of the uncertainty. The endpoints are stratified by a rough gating taxonomy: open internet (tier 0), per-call payment (tier 1), free signup (tier 2), paid subscription (tier 3), and enterprise sales contact (tier 4). For every endpoint the model has to find a path to expand its individual information frontier by gaining access to the endpoint.
Gemini brings back the largest payloads (around 475 kbit per attempt on average, about seven times what Codex extracts) and has the lowest no-path-found rate of the three (3.5%, vs. Codex's 8.5% and Opus's 9.2%). Codex has the highest bits-per-token efficiency (314 bits per token, vs. Gemini's 284 and Opus's 123). Opus has the highest rate of fully fetching the requested data (around 27% of all attempts across the five tiers, with Codex and Gemini close behind at 23% and 22%). The spread between models on any of these measures is smaller than the spread between tiers, where pass rate drops from about 77% at tier 0 to zero at tier 4. The load-bearing bottom line here is that the access layer dominates the model layer.
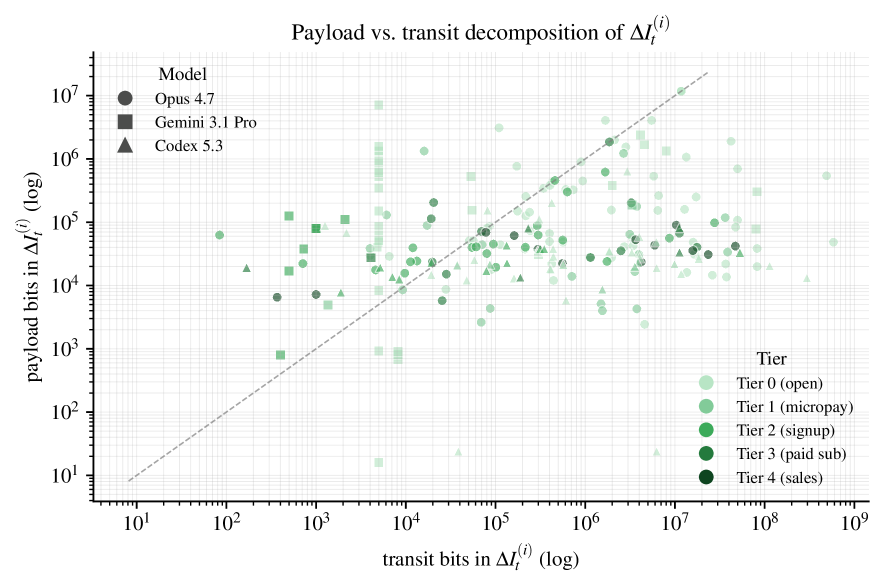
Agents overwhelmingly fell short at payment and identity walls. So what's binding the information frontier at the agent layer right now is access. Similar observations have been circulating in agent-eval work, framed variously as a knowledge–action gap [rt26] or a reliability constraint [xw26, is26].
Closing the gate-shaped failure mode is access-infrastructure work. All this is ultimately the underwriting motivation for why we started Brickroad. We [mc26] and others [ys26] also have ongoing open-source efforts to make information frontier expansion smoother and cheaper: Croissant gives datasets machine-actionable provenance and governance so agents can discover, negotiate, and use them programmatically; ADP standardises the format of agent interaction traces so what one agent learns can feed the next.
Further thoughts
The next step I'm interested in is how microeconomic concepts transpose onto the frontier dynamics. Each participant (person or agent) has an individual visibility lens into the global graph and preferences over it. Preference aggregation likely runs through some sort of price: demand sums across participants who want a bit, supply is the count who can produce it inside their own budget. Prices likely decay towards cost as bits diffuse into the information plane.
For prices to efficiently aggregate information preferences and steer the frontier expansion, a couple of conditions appear mandatory: preferences need to be elicitable (recommender systems and mechanism design, with the upstream version of "what counts as good data" [sc26] ever perpetuating in sync with the information frontier); prices need to be aggregating cleanly (against trends like monopsony, attention-broker pathologies, regulatory capture); production responding dynamically (data quality has become the active constraint frontier labs organise their training-data work around [rm26, pm26], dataset releases composing where model releases come and go [pl26], realistic data its own competitive frontier [sc26a, jw26]); and the signal staying visible to whoever could act on it. Operations-layer cost decline has kept competition viable so far [bb22, mh22, sa25], but preference elicitation and market-design infrastructure for the data layer are very active areas of exploration [mc26, md26, fl26, hb26, sl26, pr26].
In many systems efficiency gains are realized through specialization. Personally, this gives me pause because in unhealthy markets it may well lead to concentration supporting rent extraction by a few that ultimately harms, not helps, the above desiderata. We can already see this at the model and hardware layers, and one tier higher again at the access layer.
But we also have a time-tested recipe for healthy markets: competition, which is the exciting rallying cry for anyone carrying out work in this space across industry and research. From my point of view it ultimately boils down to this: in order to close the loop on dynamic learning systems at the current scale, we need preference aggregation mechanisms that provide a decent proxy signal — i.e. price — along which directions we want to collectively expand the information frontier. The more efficient, and under healthy competition cheap, the constituting operations become, the richer the computational graphs we can feasibly construct, the higher computational expressivity the collective information plane has, the more tasks become feasibly executable. Exciting.
References
- [cs48] Shannon, C. E. (1948). A Mathematical Theory of Communication.
- [nw48] Wiener, N. (1948). Cybernetics: Or Control and Communication in the Animal and the Machine.
- [ad24] Dubey, A. et al. (2024). The Llama 3 Herd of Models.
- [tn98] Nørretranders, T. (1998). The User Illusion: Cutting Consciousness Down to Size.
- [jz25] Zheng, J., Meister, M. (2025). The Unbearable Slowness of Being.
- [jb81] Bekenstein, J. D. (1981). Universal Upper Bound on the Entropy-to-Energy Ratio for Bounded Systems.
- [sl00] Lloyd, S. (2000). Ultimate Physical Limits to Computation.
- [sl02] Lloyd, S. (2002). Computational Capacity of the Universe.
- [jr24] Rydning, J. (2024). Global DataSphere Forecast 2024–2028.
- [mh11] Hilbert, M., López, P. (2011). The World's Technological Capacity to Store, Communicate, and Compute Information.
- [dr18] Reinsel, D., Gantz, J., Rydning, J. (2018). Data Age 2025: The Digitization of the World from Edge to Core.
- [rl61] Landauer, R. (1961). Irreversibility and Heat Generation in the Computing Process.
- [hv26] @hadivafaii (2026). Landauer / Bennett / Maxwell's Demon — thread on irreversibility and the entropy cost of erasure. link
- [sa25] Stanford HAI (2025). AI Index Report 2025.
- [ep25] Epoch AI (2025). Inference Cost Trends.
- [aa26] @ArtificialAnlys (2026). Coding Agent Index — (model, harness) benchmark launch. link
- [yl22] LeCun, Y. (2022). A Path Towards Autonomous Machine Intelligence.
- [gh22] Hinton, G. (2022). The Forward-Forward Algorithm: Some Preliminary Investigations.
- [fc19] Chollet, F. (2019). On the Measure of Intelligence.
- [hk20] Küttler, H., Nardelli, N., Miller, A. H., Raileanu, R., Selvatici, M., Grefenstette, E., Rocktäschel, T. (2020). The NetHack Learning Environment.
- [ta24] Akiba, T., Shing, M., Tang, Y., Sun, Q., Ha, D. (2024). Evolutionary Optimization of Model Merging Recipes.
- [yl26] @yoonholeee (2026). Meta-harness: Optimising LLM Harnesses End-to-End. link
- [ml26] @morganlinton (2026). The End of MCP. link
- [kl26] @Kangwook_Lee (2026). Why We Should Stop Designing Harnesses for AI Agents. link
- [th26] @trq212 (2026). The Unreasonable Effectiveness of HTML. link
- [rs19] Sutton, R. (2019). The Bitter Lesson.
- [jw25] @_jasonwei (2025). Asymmetry of Verification and Verifier's Law. link
- [xw26] @xwang_lk (2026). On the Reliability of Computer Use Agents. link
- [is26] @istoica05 (2026). Reliability as a First-Class Design Objective for Agentic AI. link
- [rt26] @rosstaylor90 (2026). Frontier Models' Long-Horizon and Knowledge–Action Gaps. link
- [mc26] @MLCommons (2026). Croissant 1.1 — machine-actionable dataset provenance and governance. link
- [ys26] @yueqi_song (2026). Agent Data Protocol. link
- [un24] United Nations DESA (2024). World Population Prospects.
- [wc20] Cathcart, W. (2020). WhatsApp Daily Message Volume.
- [wr23] WordsRated (2023). Academic Publishing Statistics.
- [lb21] Bornmann, L., Haunschild, R., Mutz, R. (2021). Growth Rates of Modern Science: A Latent Piecewise Growth Curve Approach.
- [sc26] @seanzcai (2026). "What Is Good Data?" link
- [rm26] @RicardoMonti9 / @datologyai (2026). Überweb — Data Quality as the Binding Constraint at 20T+ Tokens. link
- [pm26] @pratyushmaini (2026). Finetuner's Fallacy — thread through rephrasing the web, safety pretraining, TOFU. link
- [pl26] @percyliang (2026). On Preferring Dataset Releases over Model Releases. link
- [sc26a] @seanzcai (2026). Data Markets Reacting to the Realistic-Data Ceiling. link
- [jw26] @jaseweston (2026). AutoData — Agentic Data Scientist Converting Inference Compute into Higher-Quality Training Data. link
- [bb22] Backblaze (2022). Hard Drive Cost per Gigabyte over Time.
- [mh22] Hobbhahn, M., Besiroglu, T. (2022). Trends in GPU Price-Performance.
- [md26] @Melt_Dem (2026). Data Representation and Optimality. link
- [fl26] @Freeman_Lewin (2026). What Hath God Wrought: The Geometry of Data Markets and the Path to Data Liquidity. link
- [hb26] @herbiebradley (2026). On the Algorithmic-Efficiency Framing Structurally Sidelining Data. link
- [sl26] @hypersoren / Soren Larson (2026). Cybernetic Arbitrage: Context, Sensors, and Where Value Accrues in the AI Economy. link
- [pr26] @pratapranade / Pratap Ranade (2026). Data Doesn't Fuel AI. Entropy Does. link
Originally published as an article on X.