Changelog #3: Source Streams — Data Supplier Discovery on Autopilot
Source Streaming is now live on Brickroad. Set your thesis once, and your agent runs continuously, notifying you the moment a new data supplier comes online. Plus new APAC supplier discovery across China, Japan, Korea, and India; established-supplier views alongside frontier sources; and workspaces with category views for organizations running concurrent queries.

By the time a data supplier shows up in a directory, the alpha is already gone.
That has always been the dirty secret of data sourcing. The directories, the catalogs, the curated lists of "alternative data providers" — they are useful, but they are lagging indicators of alpha. A vendor only lands in one of these catalogs after they have built a website, hired a salesperson, and shopped themselves to enough buyers that an analyst notices. By then, the first ten funds, AI labs, and corporates have already signed contracts. The information edge has dissipated into consensus.
We launched the Information Frontier Agent to compress that lag. An agent that searches the open and closed web, reads filings, forums, app reviews, and proprietary data resources, follows citation graphs, and surfaces data suppliers before they show up in the directories. It worked. So clients started asking for the obvious next thing: don't make me run the agent. Make the agent run on its own. Tell me the moment something new appears.
Today, that tool is live. We call it Source Streams, and it is the most impactful tool you'll use this year.
This post walks through what shipped over the last few weeks — Source Streams, APAC supplier discovery, established-supplier views, and workspaces with category views — and what comes next.
What is a Source Stream?
On Brickroad, a Source Stream is a continuous, agent-driven feed of novel data suppliers that match a thesis you define. The agent runs in the background indefinitely, scanning the complete corpus of its resources to find new suppliers that fit your criteria. Every time it finds a new supplier, the agent notifies you and logs the source into your lead table.
Think of it as a saved search that never stops running, with an agent doing the searching instead of a keyword matcher.
The mental model is simple:
- Define a thesis. Plain English. "Consumer foot traffic data outside the US," "Cybersecurity zero-day feeds," "Logistics route optimization datasets in APAC."
- Set a cadence. Real-time, hourly, daily, weekly. Streams run as often as your tier supports.
- Walk away. The agent searches continuously, deduplicates against your existing pipeline, and surfaces only suppliers it has not shown you before.
- Triage as they arrive. New sources land in the stream feed with a relevance score, supplier metadata, and a one-click path to enrich or contact.
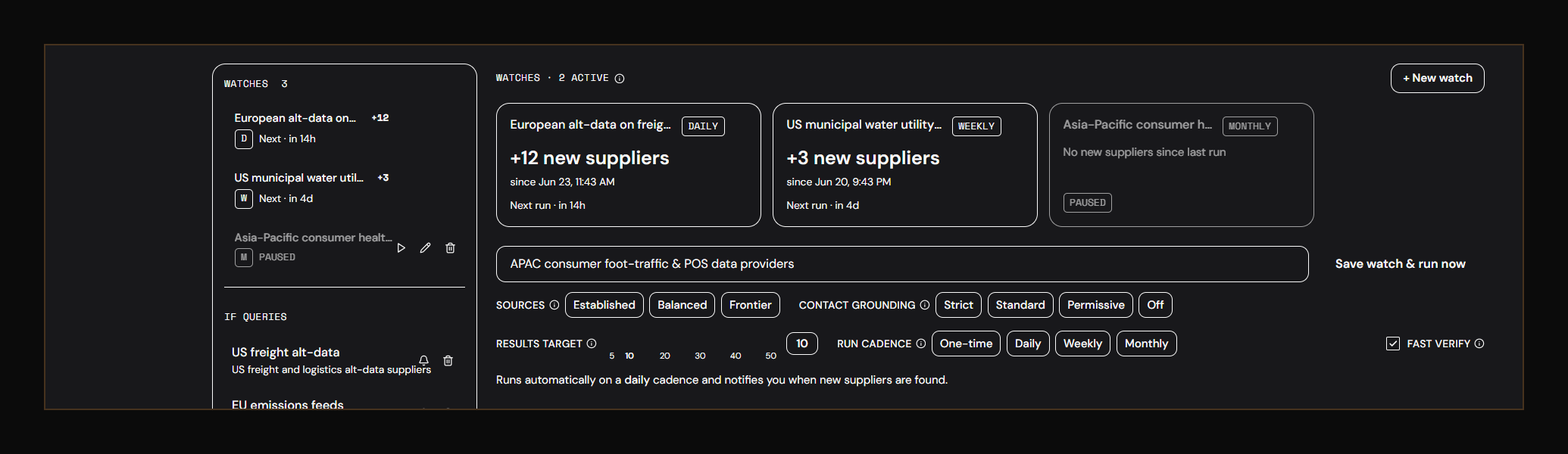
Source Streams are live for Pro and Enterprise clients. They are the first sourcing primitive we know of in the financial services space that treats discovery as a continuous infrastructure problem rather than a one-time search.
Why continuous discovery beats periodic search
The information frontier is expanding faster than humans can comb it. In the alt-data space alone, the alternative-data market reached an estimated $18.8 billion in 2025 and is growing rapidly. Most of that growth is new supply: providers spinning up niche datasets, first-party companies waking up to the fact that their exhaust has value, scrapers commoditizing the long tail. The supply curve is steepening, not flattening.
In a market with steep new supply, the time between a supplier coming online and the first buyer signing a contract is the entire game. That window is shrinking. A quarterly sourcing sweep used to be enough. A monthly one stopped being enough sometime last year. The buyers winning right now are the ones running discovery continuously.
Source Streams are that loop, automated.
For buyers whose competitive advantage depends on getting to a supplier before their peers — hedge funds, AI labs building proprietary corpora, strategic procurement teams — this is not a convenience. It is a structural advantage. Frontier supply has a half-life. Source Streams are designed for that half-life.
APAC Supplier Discovery
The second major shipment is a new sourcing module covering the four major APAC corridors: China, Japan, Korea, and India.
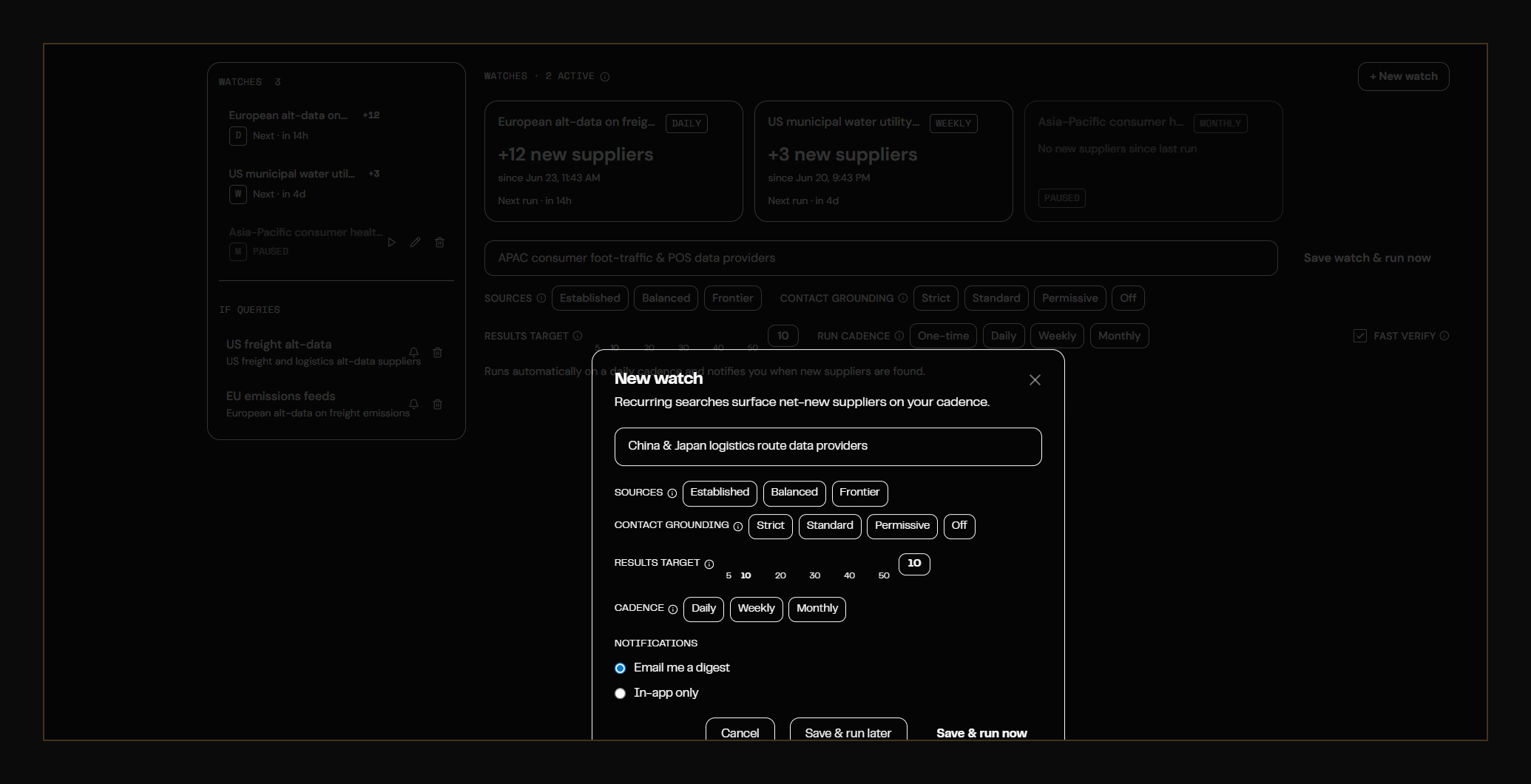
APAC supplier discovery has always been the hardest part of the job for Western buyers. Most directories under-index the region. Vendor websites are often Chinese-, Japanese-, or Korean-language only. Listing conventions diverge: a Tokyo data co-op publishes differently than a Hangzhou aggregator, which publishes differently than a Bengaluru SaaS shop selling raw logistics feeds as a side product. The result is that a generic English-language search misses most of the supply.
The new module solves this with region-aware agents: search routines that route queries through region-appropriate sources, language models, and citation graphs. Last week we shipped a foundational relevancy awareness update; this week we layered region awareness on top. The agents now know not just what to look for, but where, and in what language to look for it.
The APAC module ships in two layers:
| Layer | Plan | What you get |
|---|---|---|
| Base APAC discovery | Free, all plans | Region-aware search across CN / JP / KR / IN. Results surface in your lead table alongside global sources. |
| Advanced APAC module | Pro and Enterprise | Advanced search and inference, contact mapping for surfaced suppliers, ability to wire APAC sources into Source Streams. |
We made the base APAC discovery free because we want the entire customer base — including users still on the basic plan — to be able to see APAC supply. The depth of access, contact mapping, and continuous-stream behavior is where the paid tier kicks in.
Established Supplier Views
The Information Frontier Agent is named for the frontier. But not every job is a frontier job.
Sometimes you want the consensus supplier alongside the novel one. A hedge fund running a backtest may want to know the Bloomberg-grade reference dataset and the niche feed that nobody has touched. A corporate procurement team may need the established vendor for primary coverage and the frontier supplier as a hedge. The frontier without the floor is not a complete picture.
So we added an established supplier column to the lead table. You can now sort, filter, and pivot your results to see consensus suppliers next to frontier ones — and decide, deal by deal, which side of the curve you are buying from.
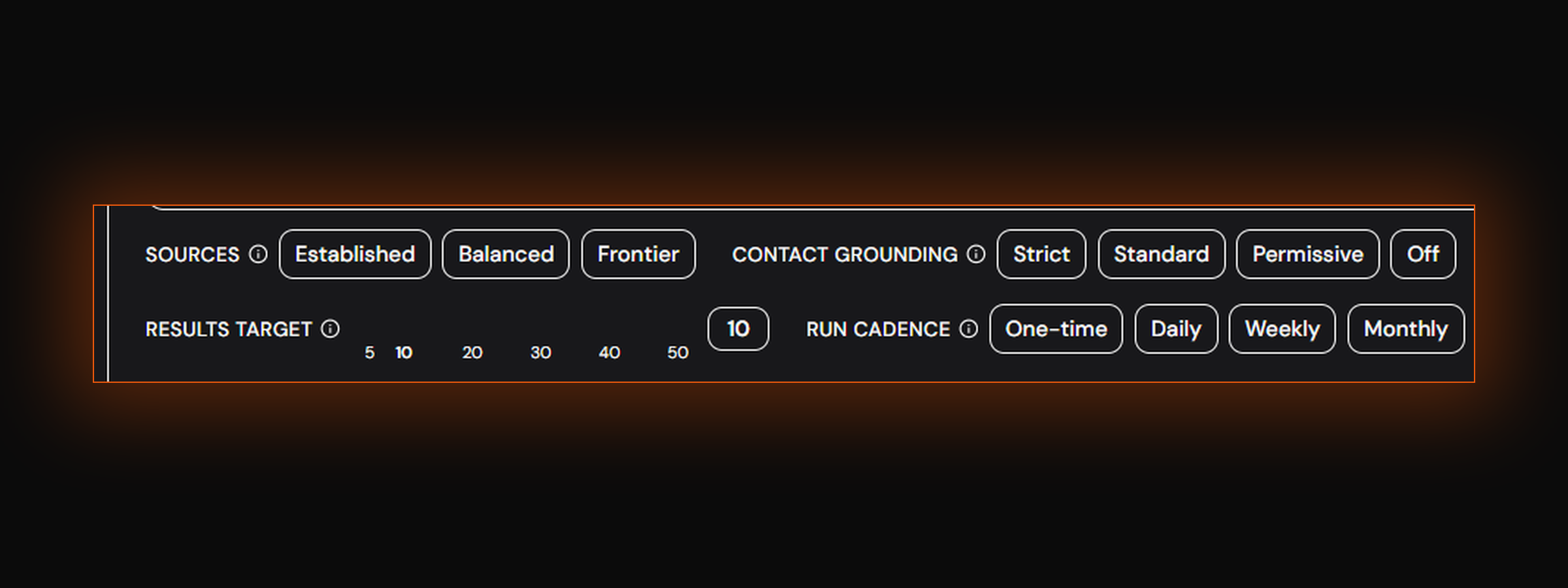
We also added several prominent data catalogs to our tracking list. The agent now indexes them as part of its baseline pass, which means established suppliers surface faster and the frontier vs. established distinction is sharper than it was a month ago.
Two practical patterns clients are running on this:
- Frontier-first, established as floor. Set Source Streams on novel supply. Use the established column as a fallback when the frontier comes up short for a given thesis.
- Established-first, frontier as edge. Buyers with mandates that require established providers (compliance, audit, vendor-management policy) use the established view as their primary surface, and treat frontier as the upside discovery layer.
Both are valid. The point of shipping this column is that you no longer have to choose which view of the market to optimize for. You can hold both at once.
Workspaces and Category Views
For organization administrators, this update is the one that quietly changes the most.
You can now spin up workspaces from the top navigation, and invite users to a specific workspace or pod. Each workspace carries its own queries, Streams, category views, and rules. Teams running concurrent theses get their own space; no more accidentally crossing wires with a colleague's queries, no more shared inboxes that mix three workflows into one.
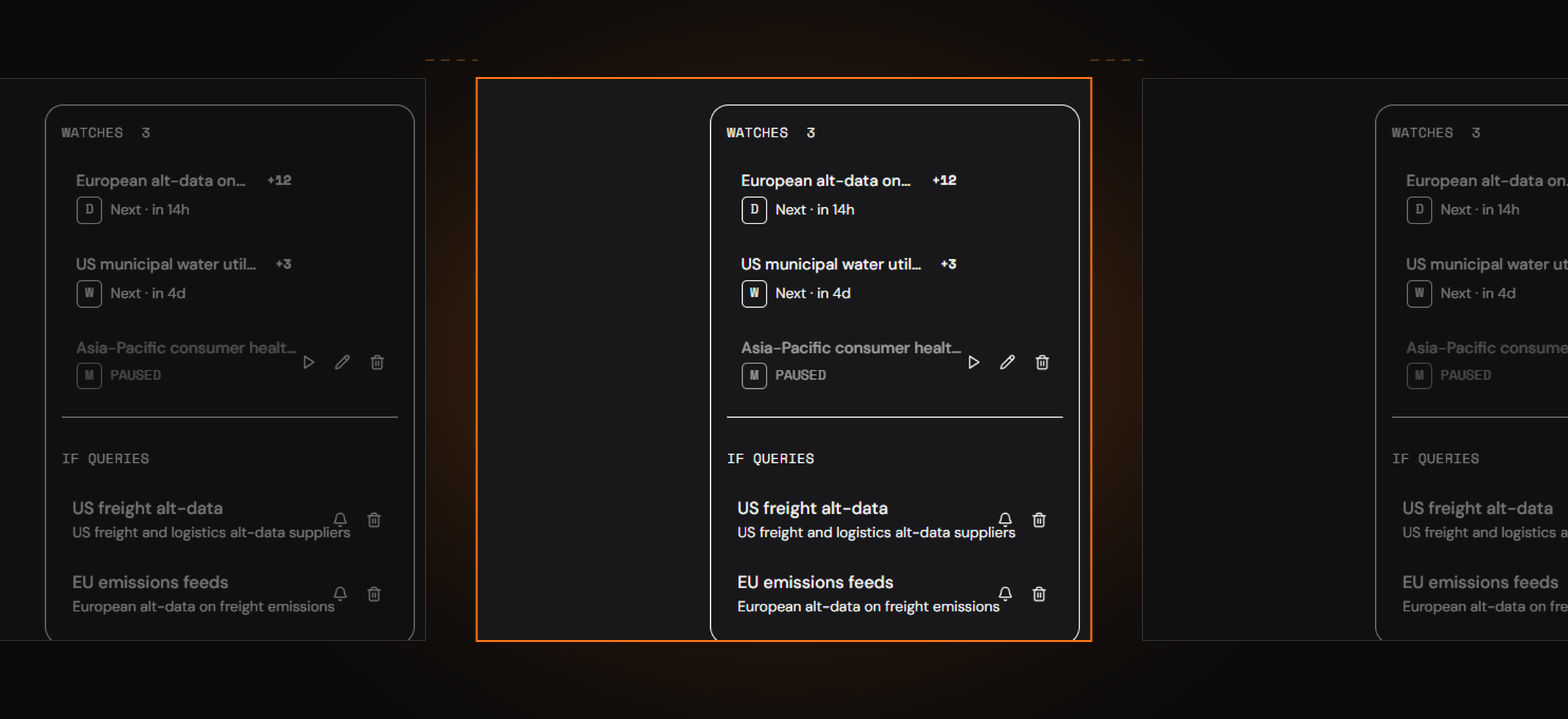
Category Views work inside workspaces. Create folders, organize queries by sector or strategy, and deputize owners for specific workstreams. A discretionary equity desk might run separate categories for consumer, healthcare, and energy. An AI lab might separate training-data sourcing from inference-grounding sources. A corporate procurement team might split by business unit.
The structural shift here is from one big shared list to parallel sourcing pipelines that share infrastructure but not state. For solo users this is invisible. For organizations running three, five, or fifteen concurrent theses, it is the difference between an agent platform that scales with you and one that becomes a swamp on day 90.
What shipping next
The roadmap for the next few weeks revolves around the understanding that discovery is only the first leg of the sourcing problem. Once you have found the supplier, you still need to talk to them, sample their data, contract with them, and manage the relationship. Most of that work today is unstructured email, ad-hoc Slack threads, and contracts spread across legal, finance, and the desk that actually uses the data.

Three things shipping in the coming weeks:
- Agent inboxes for vendor outreach and sample collection. Your agent runs the cold outreach, schedules the calls, requests the samples, and triages responses into a structured inbox you actually want to open. Every conversation is tied back to the supplier record. No more lost threads.
- A network mesh to track, enrich, and connect to existing resources. Suppliers you already have, suppliers your peers reference, suppliers buried in citation graphs — the mesh organizes them as a graph, not a list, and lets your agent traverse it intelligently.
- A vendor management tool for organizing contracts and monitoring usage. License terms, renewal dates, usage volume, cost-per-query, who on the team has access — all in one surface, tied to the sourcing record that originated the deal.
Together, these three layers turn the Information Frontier Agent into something larger: a continuous sourcing, contracting, and management system. Discovery is the first stop. We are building the rest of the route.
If you want a sneak peek of any of the above, reach out.
Frequently asked questions
What is the Information Frontier Agent? Brickroad is a frontier lab building agentic infrastructure for data provisioning. The Information Frontier Agent is Brickroad's discovery tool for sourcing data suppliers. The IFA uses proprietary routing and sources to identify and predict businesses that may have relevant data as an extension of their operations, and would be likely to license the same.
What is a Source Stream? A Source Stream is a continuous, agent-driven feed of newly discovered data suppliers that match a thesis the user defines. The agent runs indefinitely in the background and notifies the user every time it finds a new supplier that fits the criteria. Source Streams are available to Pro and Enterprise clients.
How is this different from a data marketplace? A data marketplace is a catalog of known suppliers that have opted in to be listed. The IFA and Source Streams are a discovery layer for suppliers that have not yet been catalogued — newly online vendors, first-party providers, niche operators outside the major directories. The marketplace shows you the consensus; Source Streams show you the frontier.
Which APAC countries are covered? The APAC supplier discovery module currently covers China, Japan, South Korea, and India. Base discovery is free across all plans. The advanced module, which includes inference, contact mapping, and Source Stream integration for APAC sources, is available on Pro and Enterprise plans.
Can I see established suppliers alongside frontier ones? Yes. The lead table now includes an established-supplier column. Results can be sorted, filtered, and pivoted to show consensus suppliers next to frontier ones. We have also added several prominent data catalogs to the agent's tracking list to make this view sharper.
How do workspaces work? Organization administrators can create workspaces from the top navigation and invite users to specific workspaces or pods. Each workspace has its own queries, Source Streams, category views, and rules. Category Views inside a workspace let teams organize queries into folders by sector, strategy, or workstream.
Who is this for? Hedge funds and asset managers sourcing alpha-generating datasets, AI labs sourcing training and inference data, corporate strategy and procurement teams sourcing third-party data for operations, and discovery teams at data brokerages. Anyone whose advantage depends on getting to a new supplier before their peers do.
How do I get started? Pro and Enterprise clients can enable Source Streams from the Information Frontier Agent's sidebar. New users can sign up for a trial account at brickroad.network or grab time directly on Freeman's calendar.
The shorter version
Data directories are lagging indicators of alpha. Source Streams are the lead.
Set a thesis once. Your agent runs continuously across the open and closed web, reads corporate filings, forms, app reviews, and proprietary data resources — including, now, the resources from the four major APAC corridors. New suppliers land in your stream as they come online. Established suppliers sit alongside the frontier in a single lead table. Your organization runs its concurrent theses in dedicated workspaces, each with its own queries, streams, and rules.
We launched the Information Frontier Agent on the bet that discovery was the first real bottleneck in data sourcing. The bet held. Source Streams are the answer to the question every client has asked since: make it run without me.
It does, now.
If you want to put your sourcing on autopilot, reach out. The next three modules — outreach inboxes, network mesh, and vendor management — are weeks away.
Brick by Brick.