OpenML: Insights from 10 Years and More Than a Thousand Papers
A decade of OpenML, the open-source platform that turns machine-learning experiments into open, linked, and reusable knowledge. We look at the state of the ecosystem, how community-curated datasets, tasks, and benchmark suites have powered 1,500+ studies, and the lessons learned from building open-science infrastructure for ML.

TL;DR — OpenML is an open-source platform that turns machine-learning experiments into open, linked, and reusable knowledge. After ten years, this article reflects on the state of the ecosystem and its design, assesses how community-curated datasets, tasks, and benchmark suites have powered more than 1,500 studies — advancing ML research and improving reproducibility — and shares the lessons from a decade of building, maintaining, and expanding open-science infrastructure. The work brings together LMU Munich and the Munich Center for Machine Learning, Eindhoven University of Technology, Microsoft, the Weierstrass Institute and Max Planck Institute for Demographic Research, University of Freiburg, University of British Columbia, Leiden University, the L3S Research Center at Leibniz University Hannover, and Dotphoton.
Networked science for machine learning
Machine learning generates an enormous amount of experimental knowledge — datasets, models, hyperparameter settings, and results — but most of it stays trapped in individual papers, repositories, and laptops. The premise behind OpenML is simple and ambitious: make those experiments open, linked, and reusable so that the field can build on shared, machine-readable knowledge rather than reinventing baselines for every study.
Where a paper reports a single table of numbers, OpenML records the full structure of an experiment — the dataset, the task definition, the pipeline, and the run that produced each result — and links them so they can be queried, compared, and reused. This is "networked science" applied to ML: a community-curated commons that grows more valuable as more people contribute to it.
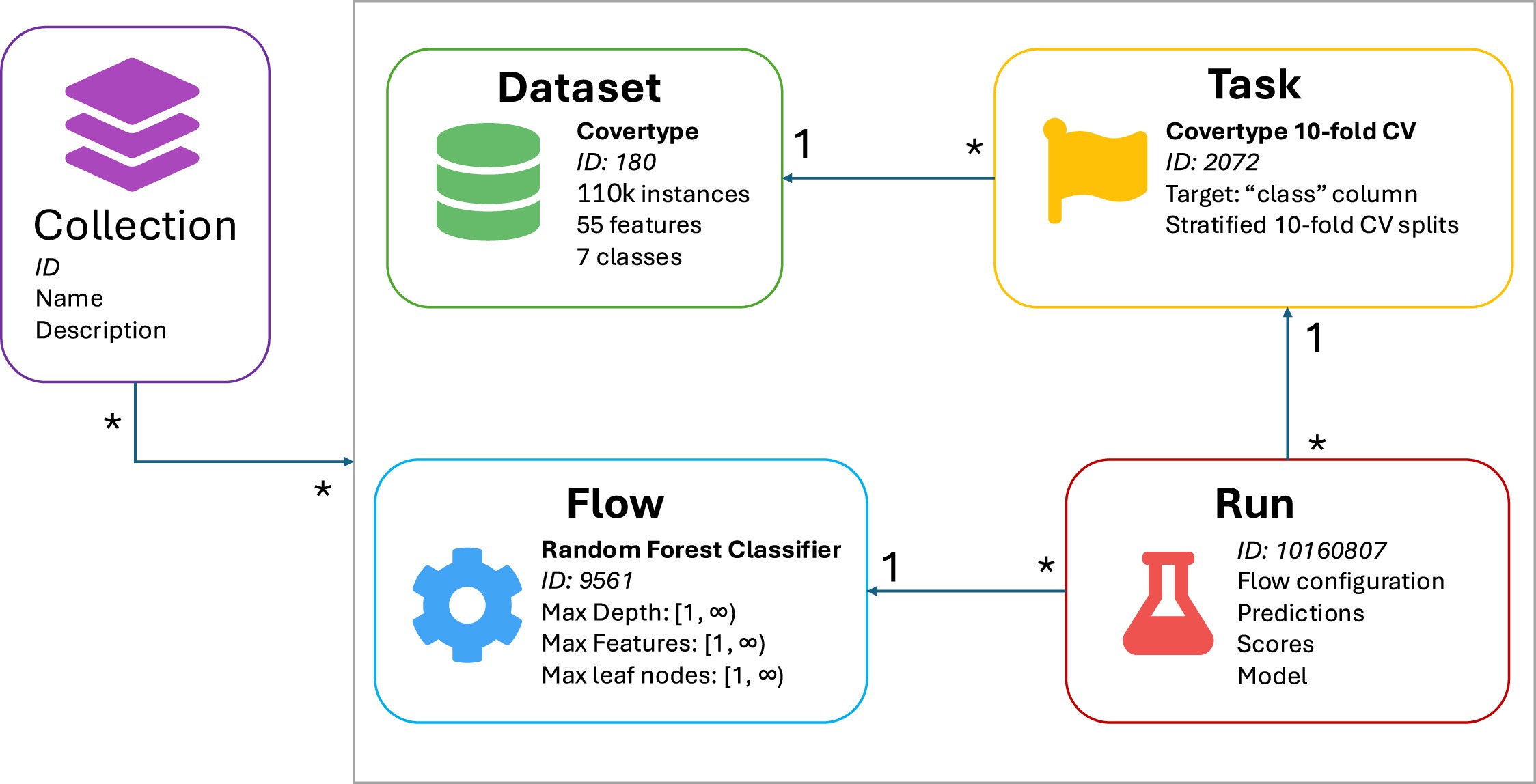
The state of the ecosystem
Ten years in, OpenML has matured into a layered ecosystem that mirrors how ML research actually works:
- Datasets — thousands of community-curated, uniformly described datasets that load directly into standard tooling, with consistent metadata that makes them findable and comparable.
- Tasks — machine-readable definitions that fix what should be evaluated and how (target, splits, evaluation procedure), so results from different studies are genuinely comparable rather than apples-to-oranges.
- Benchmark suites — curated collections such as the OpenML benchmarking suites and the AutoML Benchmark (AMLB) that give the community stable, shared targets for evaluating methods and AutoML systems.
- Integrations — first-class APIs and connectors, including OpenML-Python, the R package, and
mlr3, that meet researchers inside the frameworks they already use.
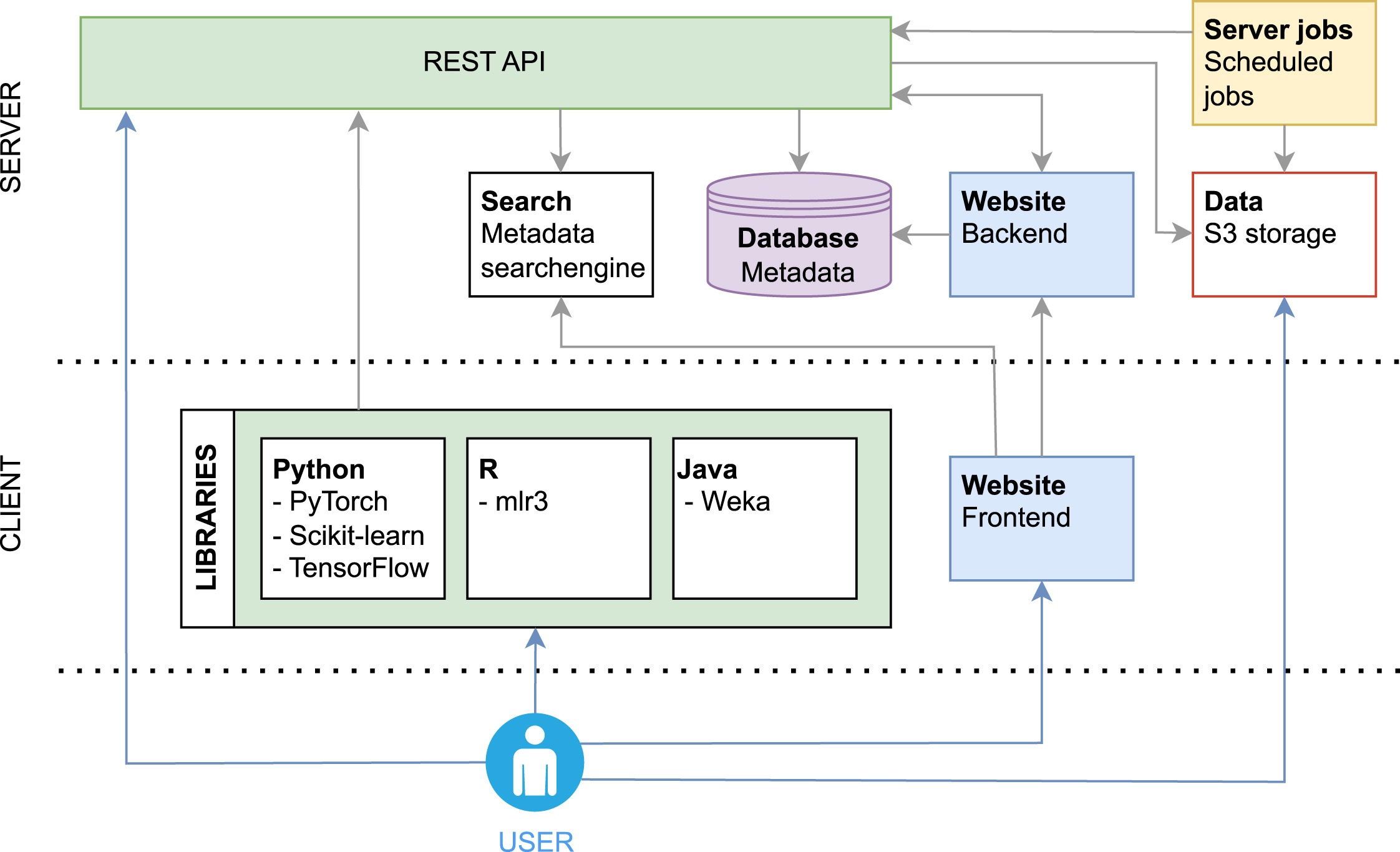
Crucially, this design is grounded in FAIR data principles — findable, accessible, interoperable, reusable — which is what lets results accumulate into a connected body of knowledge instead of a pile of isolated artifacts.
A decade of impact
The clearest signal of OpenML's value is how widely it has been used: the platform's datasets, tasks, and benchmark suites have powered more than 1,500 studies. That reach spans benchmarking, meta-learning (learning across tasks and datasets), automated machine learning, and reproducibility research — areas that are only possible at scale when experimental knowledge is shared in a structured, comparable form.
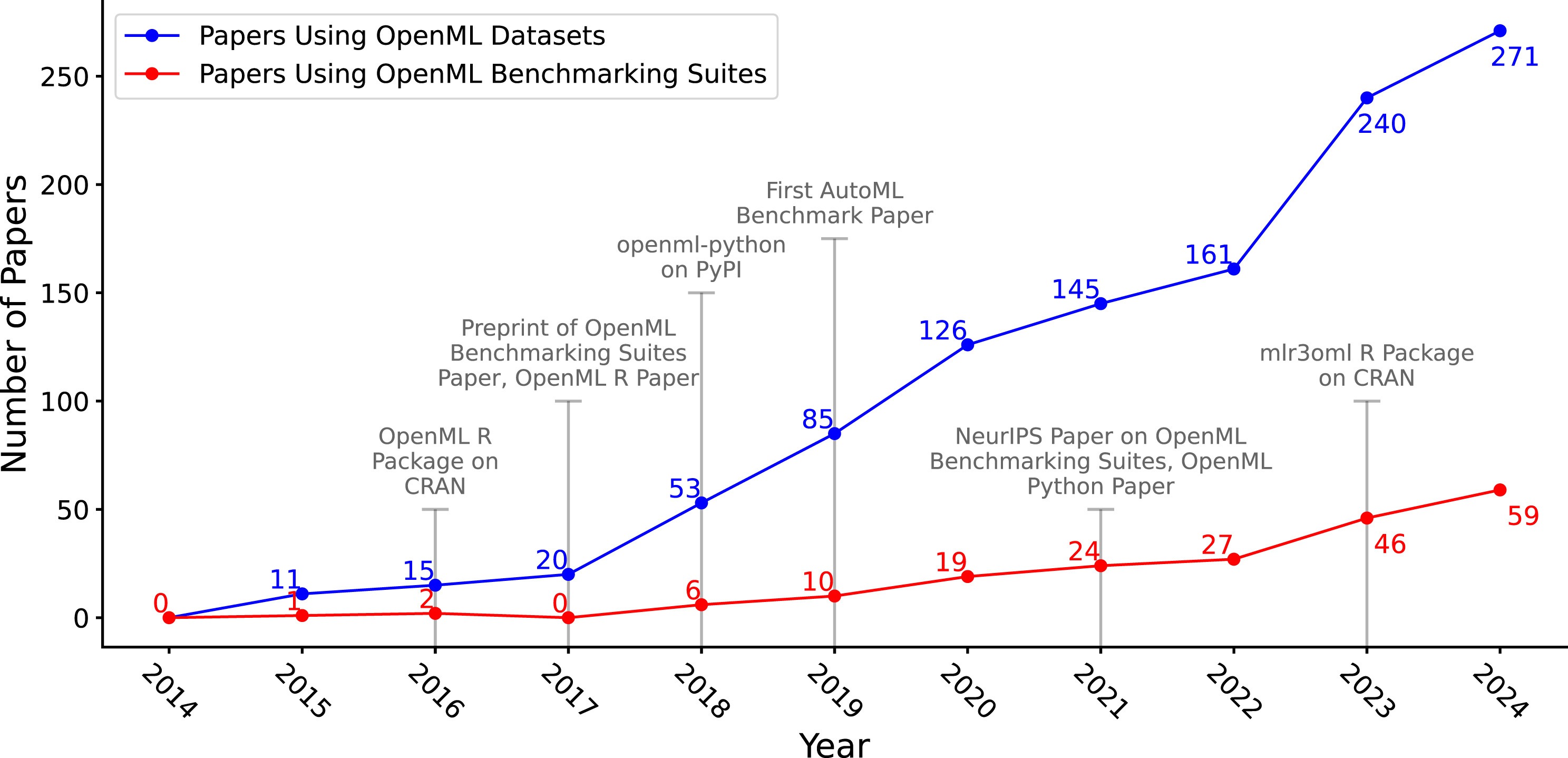
That same structure is what makes OpenML a reproducibility instrument. Because tasks pin the evaluation procedure and runs capture the full experimental context, results can be re-examined, re-run, and compared on equal footing — directly addressing the gap between a reported number and the work needed to verify it.
Lessons from building open-science infrastructure
Maintaining a living, community-driven platform for a decade surfaces lessons that go beyond any single feature. Sustaining open-science infrastructure is as much about community, governance, and long-term maintenance as it is about engineering: standards and metadata have to stay consistent as the field evolves, contributions need curation to remain trustworthy, and the platform must keep meeting researchers where they work. These reflections are offered as a guide for the next generation of open-science infrastructure for machine learning — and a reminder that the data work underpinning the field deserves the same investment as the models built on top of it.
Article and authors
OpenML: Insights from 10 years and more than a thousand papers. Published in Patterns (Cell Press), Volume 6, Issue 7, 2025. DOI: 10.1016/j.patter.2025.101317.
Bernd Bischl, Giuseppe Casalicchio, Taniya Das, Matthias Feurer, Sebastian Fischer, Pieter Gijsbers, Subhaditya Mukherjee, Andreas C. Müller, László Németh, Luis Oala, Lennart Purucker, Sahithya Ravi, Jan N. van Rijn, Prabhant Singh, Joaquin Vanschoren, Jos van der Velde, and Marcel Wever.
Affiliations: LMU Munich and the Munich Center for Machine Learning (MCML), Eindhoven University of Technology, Microsoft, the Weierstrass Institute for Applied Analysis and Stochastics and the Max Planck Institute for Demographic Research, Dotphoton, University of Freiburg, University of British Columbia, Leiden University, and the L3S Research Center at Leibniz University Hannover.