The Geometry of Data Markets
Why data marketplaces won't lead to data liquidity: lessons from history. Data liquidity is real, but it requires the right shape. Not a catalog. Not a directory. Not a platform. A multiplexer, with agents underneath, routing the right data to the right endpoint at the right time.

The Liquidity Thesis
About a month ago, Sean Cai published a great article on X positing that 2026 will be the year data becomes liquid. I agree, so much so that last year I, along with my co-founders, quit our jobs, sold a company, and chose to forego more lucrative near-term opportunities to build Brickroad to bring about that reality. But having been in the trenches of this "information services" space in what is proving to be the most transformative time in this sector's history, I can tell you that the path to liquidity is not the one most people imagine.
Conventional venture wisdom has been something like this: AI is hungry for data, new data suppliers are emerging everywhere, and eventually supply will meet demand in some kind of functioning market. More data, more buyers, more deals, and liquidity follows naturally.
I've watched this thesis play out repeatedly across venture and beyond, and it's wrong. The achievement of "data liquidity" will not be a product of supply. It will be a product of better infrastructure, infrastructure that until recently, until Brickroad, did not exist.
The information services industry, which is comprised of data aggregators, brokers, and data-as-a-service providers, is a $200B+ market that still operates the way it did twenty years ago. When a corporation, hedge fund, or AI lab wants to acquire data, they enter into bilateral negotiations that span search, integration, contracting, licensing, cost negotiation, and quality evaluation. Each deal forces n × m wiring between sources and endpoints. Engineers build bespoke ingestion pipelines. Researchers and quants validate data quality and backtest. Legal teams review agreements. A typical enterprise data procurement cycle can take three to six months from initial discovery to production integration, with legal review alone consuming four to eight weeks (that's assuming there is even a market for the data being sold!).
Every integration is bespoke; every integration carries its own coordination overhead.
That coordination overhead is a pervasive friction, one which has choked market efficiencies in the information services industry and, by extension, innovation as a whole. And the intuitive response to this problem has always been the same: build a marketplace. If bilateral negotiation is the bottleneck, aggregate supply into a catalog, let buyers browse, and let the platform handle the transaction. It is the geometry that worked for software (app stores), for cloud compute (AWS), for labor (Upwork), and for virtually every other digital good that has achieved liquidity in the last two decades. It is also, in the case of data, wrong.
Most recently, Databricks, Snowflake, and AWS have each built "data marketplaces" intended to reduce this overhead. All three have failed to achieve meaningful adoption, landing instead on products that trend more towards product directories than programmatic data procurement networks. The reason is structural: a marketplace assumes that data can be listed, browsed, and transacted like software on an app store. But data procurement is not a catalog problem. It is a coordination problem. Every dataset requires schema negotiation, format alignment, licensing review, and quality validation before a buyer even knows whether the data is useful. A marketplace can list the inventory, but it cannot perform the work of matching, evaluating, and integrating that inventory to a buyer's specific needs. Data simply does not sell itself.
To understand why marketplaces are not, and will never be, the substrate for data liquidity, I think it is important to understand the geometry of data markets: the shape of how information has always flowed between those who have it and those who need it.
This post traces that evolution, from before the telegraph to the transformer, revealing how the geometry shifted in each cycle, where opportunities surfaced, and why incumbents lost. The pattern that emerges presents the current moment as a unique and underappreciated opportunity for those willing to build the infrastructure that makes data liquid.
The Landscape
Before tracing the history, it helps to map the current geometry: who sits on each side of the data market today, and why the shape of their interactions matters.
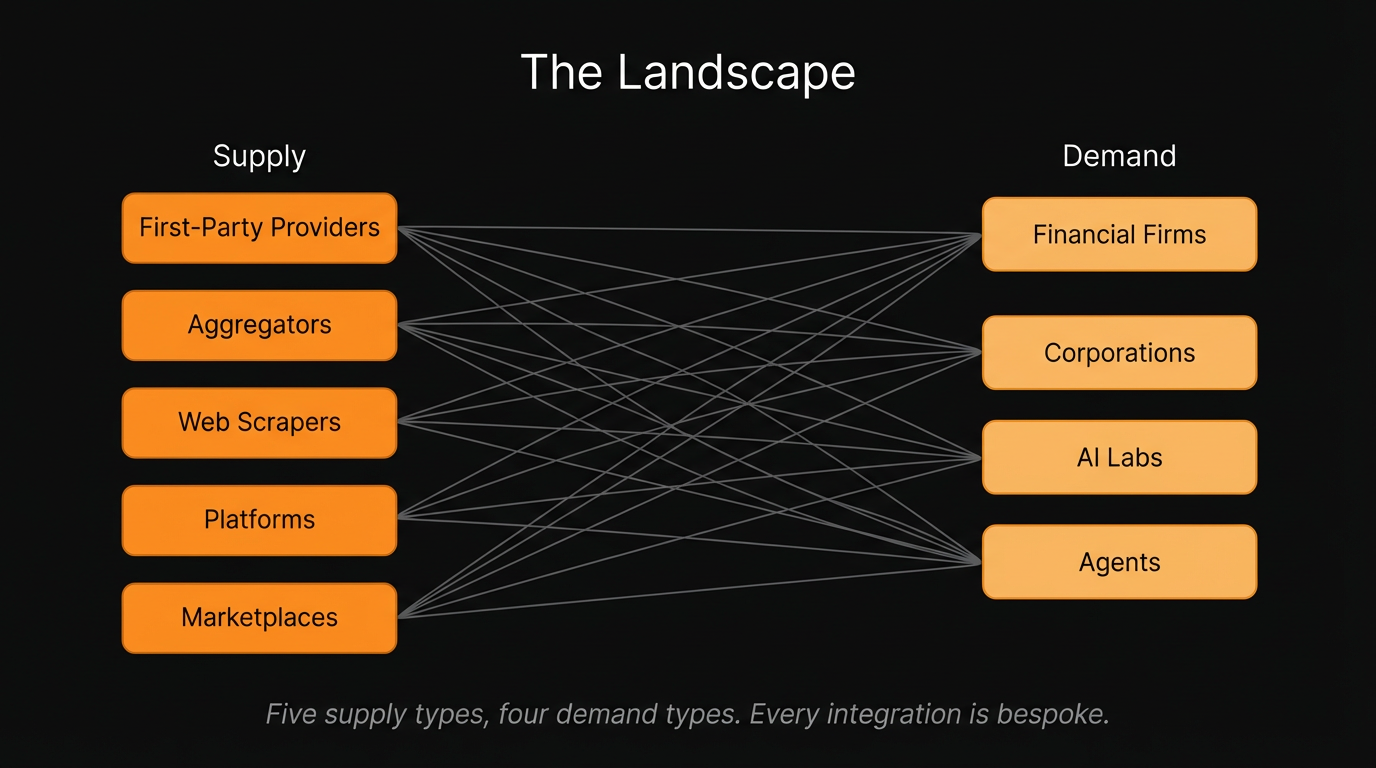
On the supply side, there are five distinct players. The first, and most valuable, are first-party data providers: companies that generate proprietary data as a byproduct of their core operations but do not think of themselves as data companies. A logistics firm sitting on years of shipping route optimization data. A healthcare network with decades of patient outcome records. These are the sources with the most alpha, precisely because their data has never been leveraged, for trading, research, training or otherwise. For many paying users of data, the value of a dataset is in its private state; and the moment it is listed on a public marketplace, that value begins to erode.
Second are aggregators. These companies take title of a dataset from a first-party provider, paying upfront with either cash or tokens, and license it downstream to buyers. They make money on the spread. They exist because first-party providers often lack the infrastructure or incentive to sell directly, and buyers lack the networks to find them. It is a risky endeavor to pay for data up front without a full picture of the geometry of this market, and many, especially in the crypto space, have and will continue to, fail as a result.
Third are web scrapers, who crawl public data en masse: pricing feeds, job postings, product listings. It is a commodity play. The data is available to anyone willing to build the crawler, so margins compress quickly.
Fourth are platforms, such as Bloomberg, or increasingly, vertical SaaS providers that integrate data from the first three categories into a unified interface. They sell access points, not raw data. The product is answers, not files. The model is subscription-based, and the moat is workflow integration.
Fifth are marketplaces, including Snowflake Marketplace, AWS Data Exchange, and Databricks Marketplace. These sell raw data on a per-transaction basis. Browse the catalog, evaluate a sample, purchase the dataset. It is the model most people picture when they hear "data market."
Of course, the reality is messier than the above taxonomy suggests. In practice, we have found that many data suppliers do not produce neat, static datasets that can sit on a shelf waiting to be browsed and purchased. Some function more like non-deterministic search engines, returning different columns and structures depending on the query, with results that can take minutes to materialize. Others are constantly evolving feeds where freshness is the entire value proposition; a cybersecurity dataset, for instance, is worthless to an agent seeking zero-day exploits if the data is even a few hours stale. Still others are continuously enriched, making it difficult to even define what version of "the dataset" a buyer is purchasing at any given moment. Data itself resists the static, predictable inventory model that a marketplace requires.
On the demand side, three buyer types dominate. Financial firms, primarily hedge funds and asset managers, buy data for alpha. They are the most sophisticated buyers, the most demanding on quality, and the most sensitive to exclusivity; if everyone has the same dataset, it is worthless to them. More importantly, these buyers are not looking for commodity data that can be browsed in a catalog. They are looking for data at the information frontier: novel, unexplored sources that no one else has found yet. The very act of purchasing a dataset through a visible marketplace erodes its value, because the purchasing pattern itself is an alpha signal. If a marketplace operator can see what a fund is buying, the fund's strategy is partially revealed. Demand-flow visibility is not a feature for these buyers; it is a dealbreaker. Corporations buy data to augment their business operations: market research, supply chain intelligence, competitive benchmarking. Their needs are broader, their compliance requirements are different, and their procurement cycles are longer. AI labs buy data for training and inference, large-scale and often unstructured, with licensing considerations that did not exist five years ago.
Here is what matters: each of these buyer types has a fundamentally different use case, different compliance requirements, and buys different types of data for entirely different reasons. The demand side is not a uniform market. It is deeply heterogeneous. And the most valuable buyers, those willing to pay the most for data, are precisely the ones for whom a public marketplace is structurally unacceptable. The correlation between a data deal and data alpha means that the customers with the highest willingness to pay are also the most protective of their procurement activity. This dynamic is not limited to finance; any buyer whose competitive advantage depends on proprietary information will resist a business model that exposes their demand to their competitors.
And then there are agents. Autonomous systems are emerging as a fundamentally new class of data consumer, one that does not browse catalogs or sit through procurement cycles. Agents query dynamically, composing data on-the-fly based on task requirements, selecting sources in real time rather than curating corpora in advance. An agent performing competitive intelligence for a portfolio company does not want to purchase a dataset; it wants to describe what it needs in natural language, evaluate whether the source is useful for its specific task, negotiate a license, and ingest the result, all programmatically, all without human intervention. And agents are not just proxies for human buyers. They consume data for their own inference processes, pulling in context, grounding, and real-time signals to reason better, act faster, and complete tasks that no static dataset could support. This is not a hypothetical. It is the direction the market is already moving, and it introduces a consumer whose needs are fundamentally incompatible with the browse-and-buy model. Agents do not have the patience, the process, or the institutional knowledge to navigate a marketplace. They need infrastructure that can route the right data to the right endpoint at the right time, automatically.
The Geometry of Information Markets
Every era of information infrastructure has been defined not by the data itself, but by the shape of its flow: the geometry connecting those who know to those who need to know. Each new technology collapsed one form of information asymmetry while creating another. And in every case, the winner was not the incumbent. It was the outsider who understood the new geometry before anyone else.
To see this pattern, we need to go back further than most people expect.
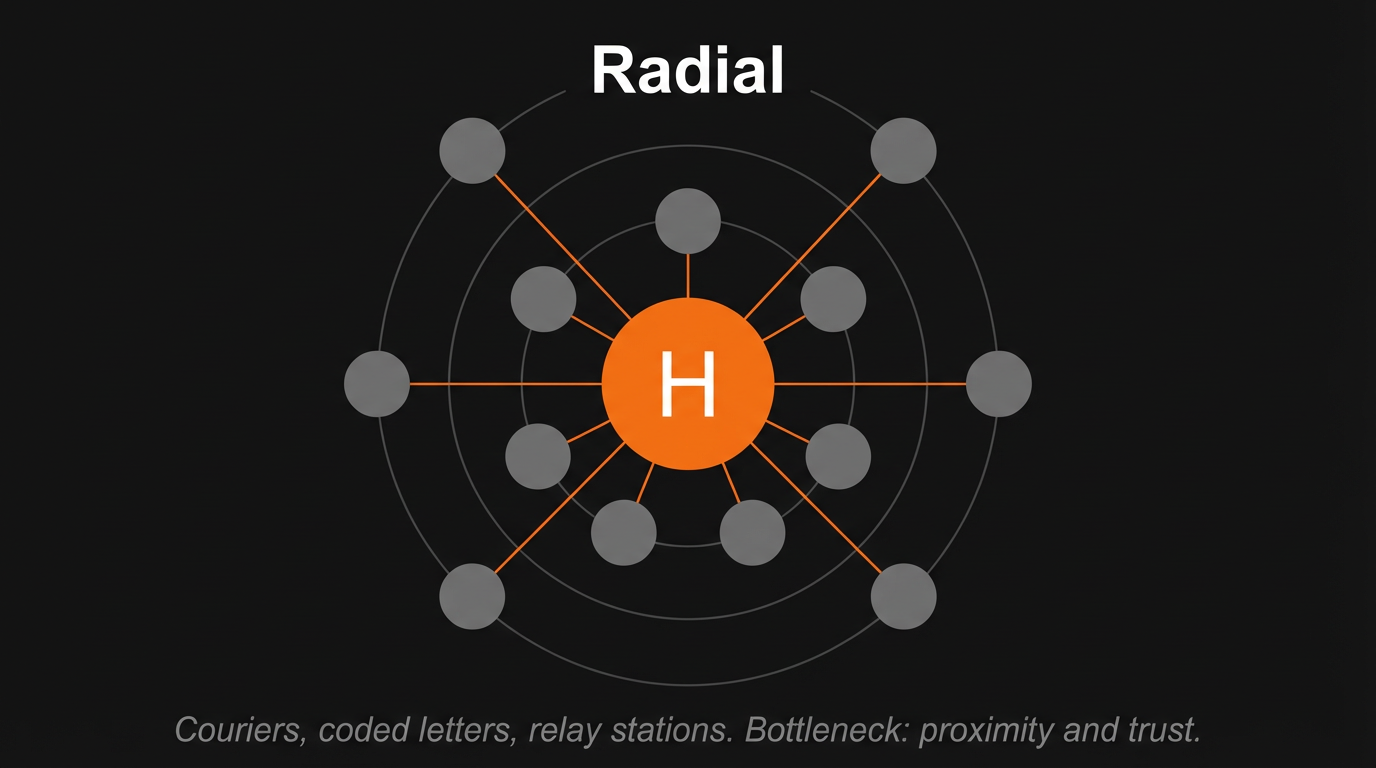
Before electronic communication, information moved at the speed of horses, ships, and pigeons. The geometry was radial, with merchant dynasties and banking houses at the center and their agents, couriers, and correspondents forming the spokes. The Rothschild family is the canonical example. Five brothers stationed across London, Paris, Frankfurt, Vienna, and Naples maintained a private courier network that transmitted commercial intelligence across Europe through coded letters and relay stations. The legend of Nathan Mayer Rothschild exploiting advance news of Waterloo in June 1815 to profit on British consols has become financial folklore's founding myth, though the historical record is more nuanced than the story suggests. What is indisputable is that the Rothschilds' information network was a genuine strategic asset, one built on physical speed and trusted intermediaries. The bottleneck in this era was proximity and trust. Information degraded with distance and time, and the intermediaries who thrived were those who could compress geography through speed and reduce uncertainty through reputation.
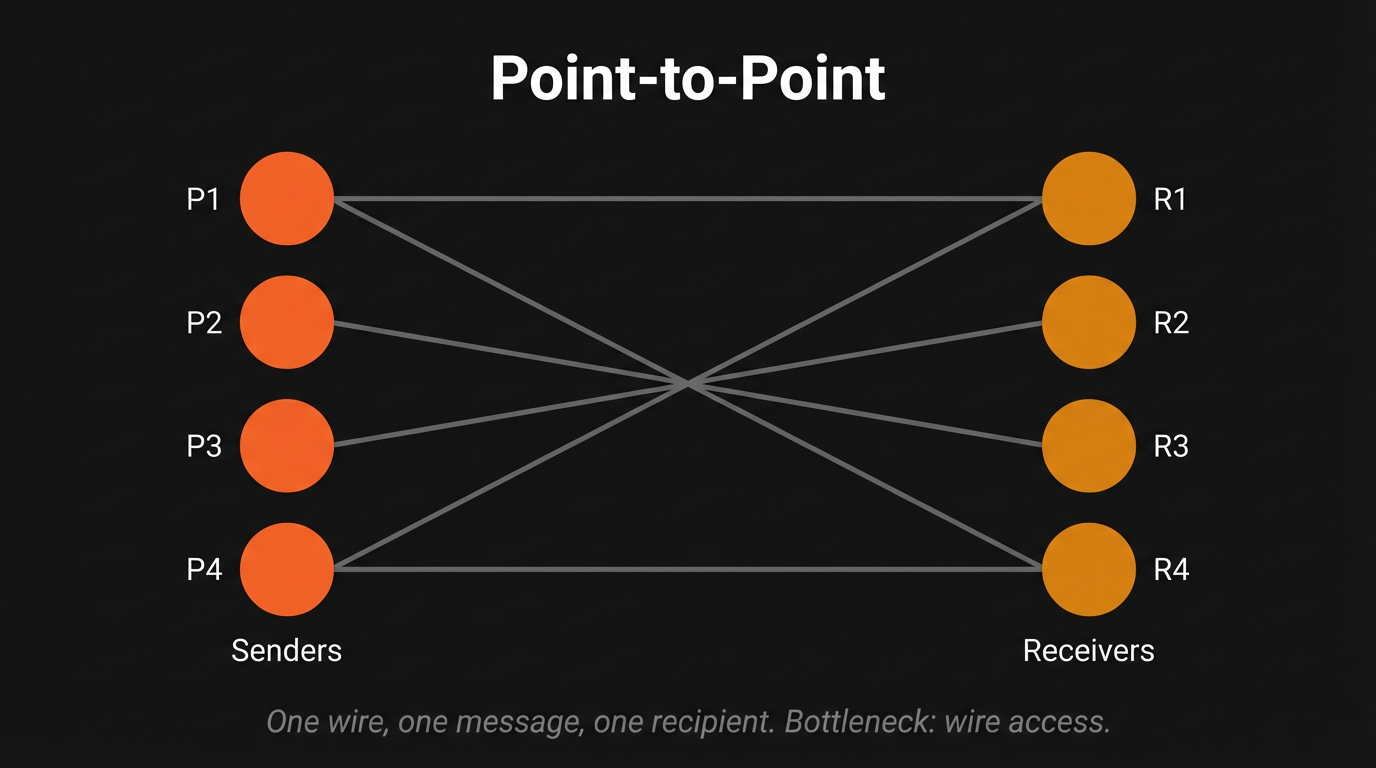
The telegraph changed everything, and it changed everything fast. On May 24, 1844, Samuel Morse transmitted "What hath God wrought?" across 44 miles of wire from the U.S. Capitol to Baltimore. Three weeks earlier, the line had already demonstrated its power: on May 1, Alfred Vail telegraphed from Annapolis Junction that the Whigs had nominated Henry Clay, news that arrived 64 minutes ahead of the train carrying the same information. The geometry shifted from hub-and-spoke to point-to-point, and the critical bottleneck moved from physical proximity to wire access.
Paul Julius Reuter understood it best. Born Israel Beer Josaphat in 1816, Reuter created an enduring legacy by spotting an opportunity that perfectly illustrates how geometric transitions create winners: a 76-mile gap in the telegraph line between Aachen and Brussels. In April 1850, Reuter was in the business of deploying pigeons to bridge the information gap between Aachen and Brussels. When the wire closed that gap, Reuter moved to London, establishing a telegraph office at 1 Royal Exchange Building to transmit stock quotes between London and Paris via the new Dover-Calais submarine cable. Thus, "Reuters" was born, not as a news organization, but as an infrastructure play on the new geometry.
The transatlantic cable completed the transformation on July 27, 1866 and its impact was immediate and measurable: cotton price differentials between New York and Liverpool fell by more than a third, and dual-listed stock price gaps shrank from 5 to 10 percent down to 2 to 3 percent. The losers were those whose advantage depended on the old geometry. James de Rothschild reportedly lamented that the telegraph had been established, for private courier networks, pony express services, and local middlemen who profited from regional information asymmetries were rendered obsolete overnight. The winners were the new intermediaries: telegraph companies and wire services that controlled the flow.
The technology changed, but the economics did not. The entity that controlled the bottleneck captured the value.
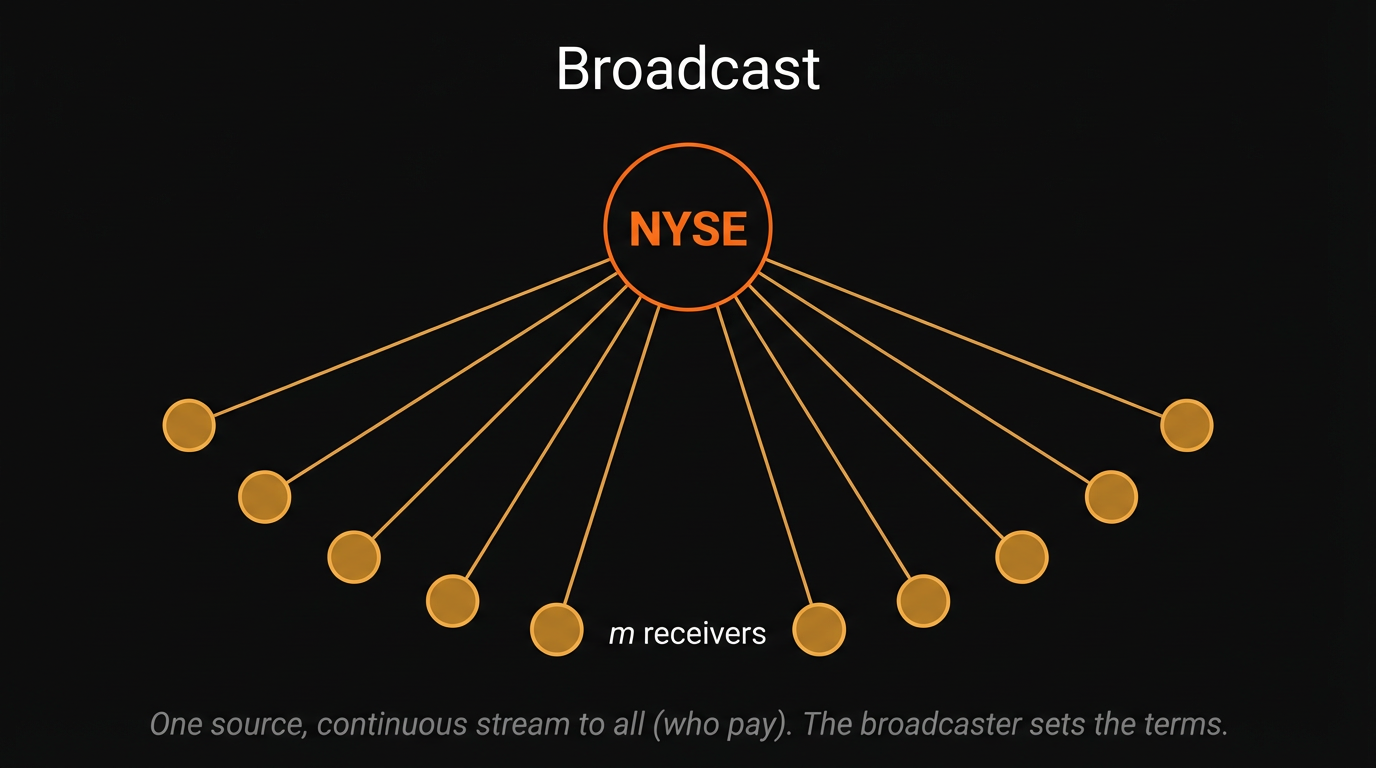
The stock ticker, unveiled by Edward Calahan on November 15, 1867, introduced a second geometric shift: from point-to-point to broadcast. Calahan, chief telegrapher at Western Union's Manhattan office, had watched messenger boys sprint from the Stock Exchange to brokerage offices and realized a machine could do it continuously. His employer, the Gold & Stock Telegraph Company, rented tickers to brokerage houses and transmitted prices to all machines simultaneously. This was structurally different from the telegraph. A telegraph message went to a specific recipient. The ticker sent a continuous stream to everyone connected, and created both a new information consumer: the tape reader, and a new fight over who "owned" the price data itself. In 1905 the Supreme Court, in Board of Trade of City of Chicago v. Christie Grain & Stock Co.*, 198 U.S. 236, ruled that exchange quotations were the property of exchanges themselves, establishing the NYSE as the de facto information monopolist. This principle persists today in the Consolidated Tape System and Regulation NMS.
Broadcast geometry democratized access but concentrated control at the source. The exchange became the single point from which all data radiated. Anyone could receive the broadcast, but the broadcaster set the terms.
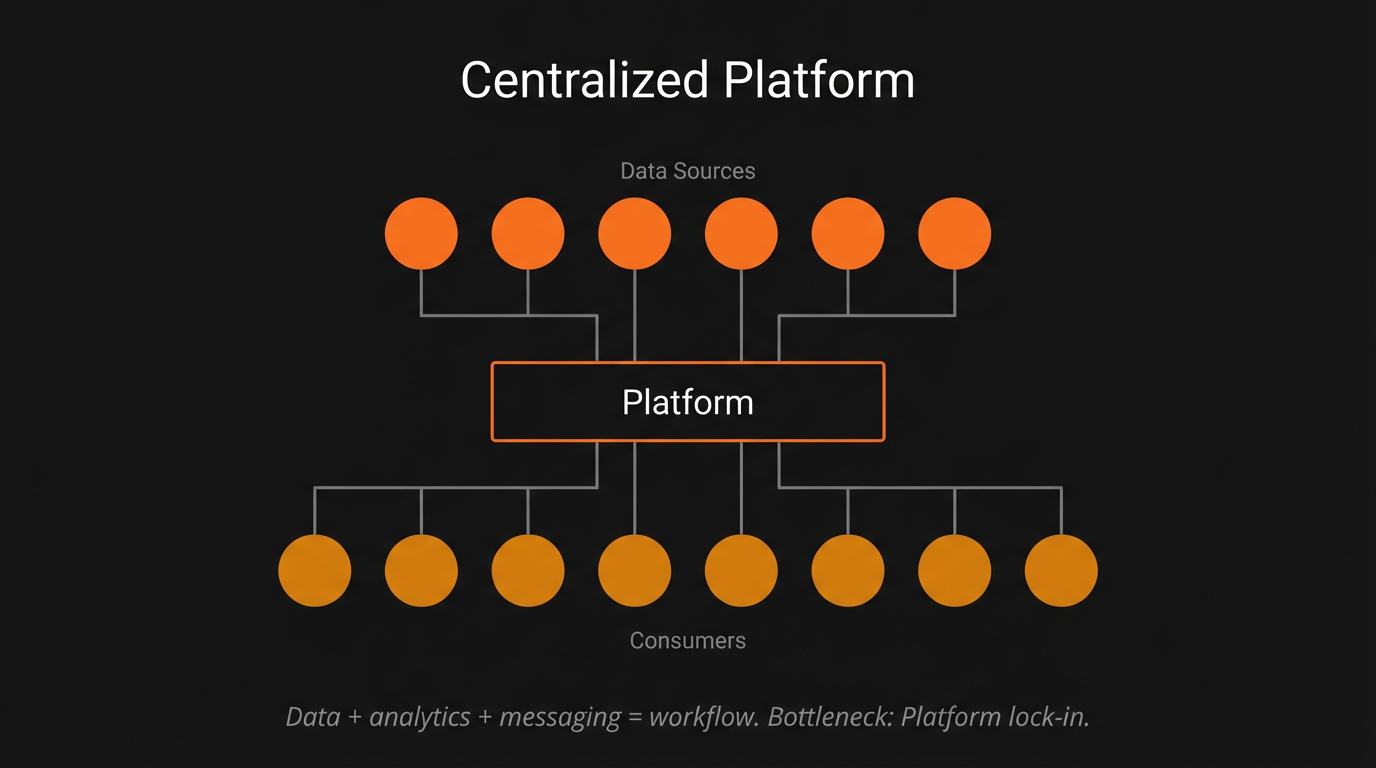
Then came the platform. As legend has it, on October 1, 1981, Michael Bloomberg, freshly fired from Salomon Brothers at age 39 with a $10 million equity buyout, founded Innovative Market Systems with three former Salomon colleagues. The first terminal shipped in December 1982 and Merrill Lynch became the inaugural customer, purchasing 20 terminals and investing $30 million for a 30% equity stake.
Bloomberg's insight, the one that separated him from his predecessors, was that the product was not data but workflow integration. The terminal bundled real-time data, analytical tools, and a messaging system into a single interface. Bloomberg Messaging became the de facto communication channel for fixed-income trading. Bloomberg handles replaced business cards. Leaving Bloomberg meant losing your analytics, your messaging network, your workflow, and your counterparty connections simultaneously. The subscription price, currently around $32,000 per year per terminal, was not a fee for data. It was a fee for the entire working environment. With over 325,000 terminals generating approximately $15 billion in annual revenue, Bloomberg achieved a lock-in that no competitor has been able to truly break.
And the competitors' failures are instructive, illustrating why incumbents never survive geometric transitions. Quotron, the first company to deliver stock quotes to an electronic screen, had 100,000 terminals and 60% market share in 1986 when Citicorp acquired it for $680 million. The acquisition drove away its largest client, Merrill Lynch, which invested in Bloomberg instead. By 1994, Quotron was down to 35,000 terminals. Telerate, a bond-price specialist acquired by Dow Jones in 1990 for $1.6 billion, was sold in 2001 bankruptcy proceedings for just $10 million. Reuters, once holding 52% global market share, saw its position erode steadily; by 2016 its successor entity, Thomson Reuters held 23% versus Bloomberg's 33%. Quotron, Reuters, and Telerate were all architecturally committed to thin clients and single asset classes. Bloomberg built from zero with a new paradigm: integrated multi-asset analytics, time-series databases, and visual interfaces. Incumbents never build from scratch, and that is why they lose.
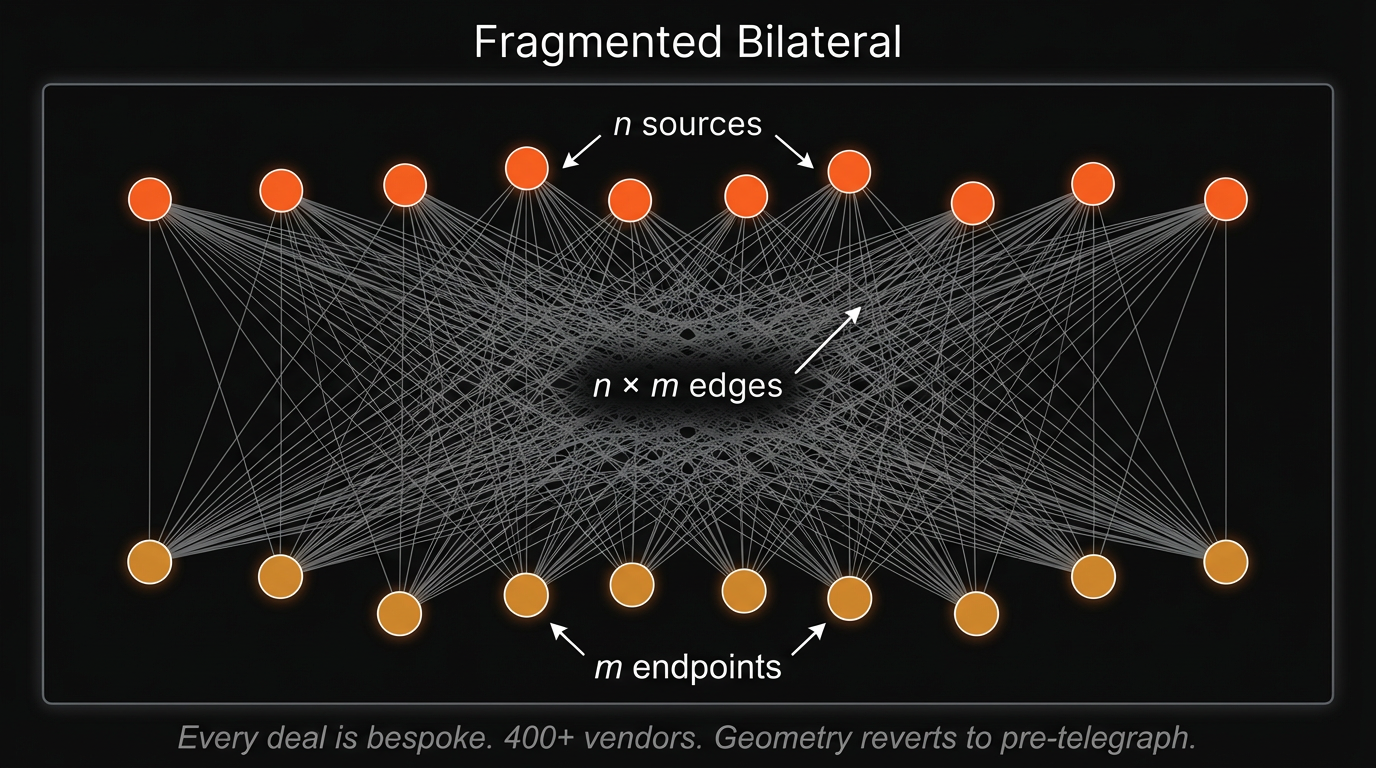
Starting in the 2010s, a new class of financial information emerged that the Bloomberg platform could not easily absorb: alternative data. Satellite imagery counting cars in Walmart parking lots. Credit card transaction feeds revealing consumer spending before earnings reports. Web-scraped job postings signaling corporate hiring surges. Geolocation data from mobile phones tracking foot traffic. The geometry shifted again, this time from Bloomberg's centralized platform to a fragmented, heterogeneous supply landscape with over 400 vendors offering wildly different datasets.
Within the investment management segment alone, alternative data spending reached $2.5 billion per year by end of 2024, growing at 33% annually.
The defining structural feature of this era is the return of bilateral negotiation. Despite multiple attempts, no centralized data marketplace has achieved dominance. The reasons are the ones we discussed in the prior section: buyers cannot assess a dataset's value without seeing it, but seeing it means partially consuming it. Data is infinitely copyable at zero marginal cost, yet its investment value depends on exclusivity. Each buyer has bespoke requirements. And the most sophisticated buyers emphatically do not want competitors to know what they are purchasing. Discovery platforms like Eagle Alpha, Neudata and Datarade (monda) act as scouts and advisors, but they do not intermediate transactions. The geometry has, remarkably, reverted to something resembling the pre-telegraph era: bilateral, relationship-driven, with trusted intermediaries reducing search costs rather than centralizing flow.
This is where the economic theory becomes instructive, and it is worth pausing on three ideas that explain why this cycle keeps repeating.
Ronald Coase argued in "The Nature of the Firm" (1937) that firms exist because using the market mechanism is costly: discovering prices, negotiating contracts, and managing exchange relationships all impose transaction costs. When these costs exceed the cost of organizing activity internally, firms bring those functions in-house. Each era's dominant information intermediary, from Reuters to Bloomberg, was the entity that most efficiently reduced the transaction costs of finding, verifying, and distributing information given available technology. The failure of data marketplaces follows Coase directly: when transaction costs for heterogeneous data remain high, due to quality uncertainty, bespoke integration needs, and trust requirements, firms build internal data teams or rely on trusted intermediaries rather than open markets.
Grossman and Stiglitz, in their landmark 1980 paper "On the Impossibility of Informationally Efficient Markets", proved formally that if markets were perfectly efficient, no one would have an incentive to spend resources gathering information, which means prices could never actually be efficient. Their resolution: markets exist in a permanent state of near-efficiency, where prices partially reflect informed traders' knowledge but leave enough inefficiency to compensate them for their costs. This maps directly onto the data market. Frontier data buyers resist transparent marketplaces precisely because transparency would erode the informational edge that justifies their investment. There is a fundamental conflict between the efficiency with which markets spread information and the incentives to acquire information.
Finally, Hayek, in "The Use of Knowledge in Society" (1945), argued that the fundamental economic problem is not allocating given resources but making the best use of knowledge of the particular circumstances of time and place: local, contextual, tacit knowledge dispersed among millions of individuals that can never be concentrated in a single entity. Alternative data is precisely this kind of knowledge. Satellite images of specific parking lots, credit card transactions from specific merchants, foot traffic at specific locations. These are inherently dispersed, contextual, and time-sensitive. They resist the standardization that centralized marketplaces require. Hayek's framework predicts that the most valuable data will always be the hardest to centralize, which explains the structural fragmentation of the alternative data landscape and, more broadly, why the marketplace model keeps failing.
The pattern is now clear. Each technology collapses the prevailing bottleneck, a new intermediary emerges to exploit the resulting geometry, incumbents fail because they are architecturally committed to the old shape, and the cycle begins again when the next bottleneck emerges. The Rothschilds lost to the telegraph. The telegraph operators lost to the ticker. The ticker lost to the terminal. The terminal lost to the platform. And the platform is now losing to a fragmented landscape it cannot absorb.
Which brings us to the current cycle.
The Current Cycle
The pattern predicts what comes next. Each cycle, a new technology collapses a bottleneck that the previous geometry could not address. Each cycle, a new entrant builds the right shape for the new reality. Each cycle, the incumbents who defined the prior era cannot make the transition. The question, then, is simple: what is the current bottleneck, and what geometry does it demand?
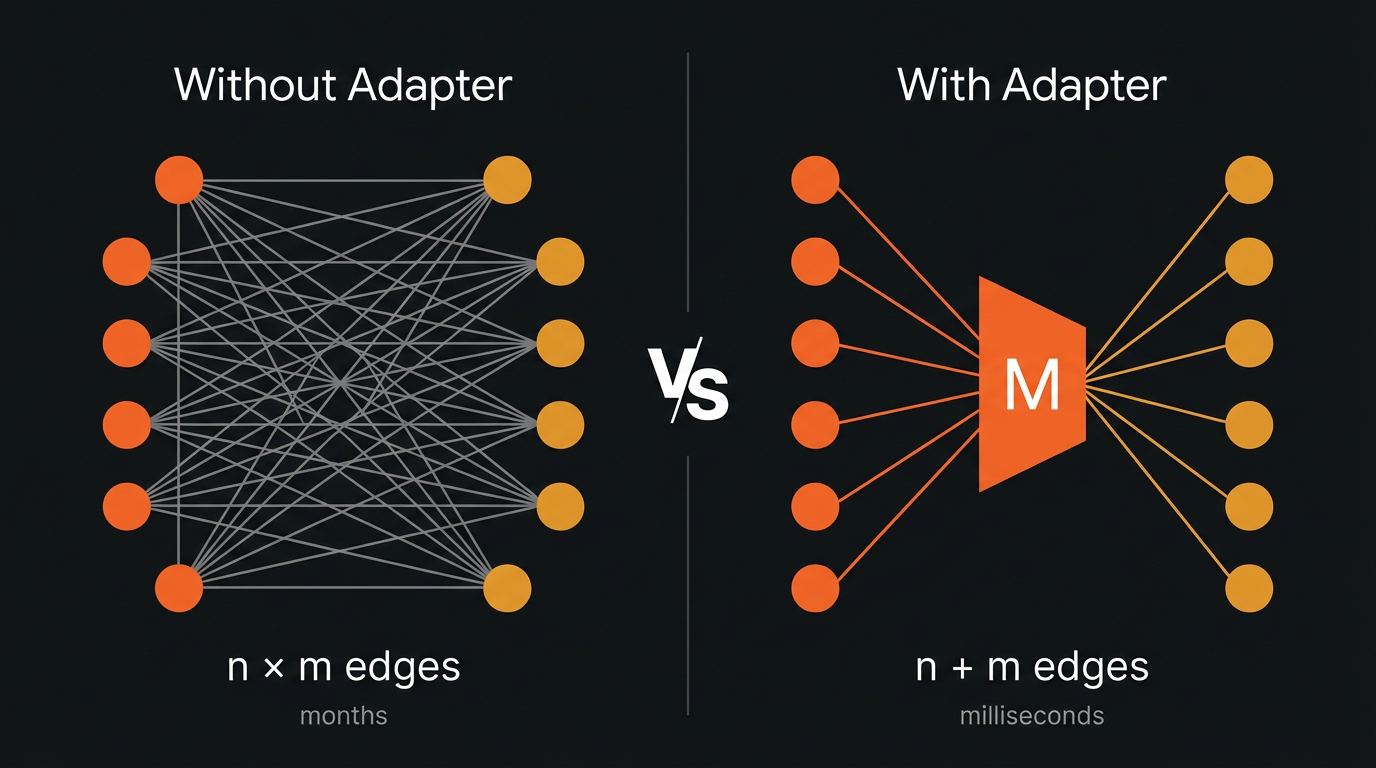
The bottleneck today is not access to data. Bloomberg solved that for structured financial information. The alternative data revolution solved it for unstructured signals. The bottleneck is not discovery either; platforms like Eagle Alpha and Neudata have catalogued thousands of datasets. The bottleneck is coordination at scale: the work of matching heterogeneous supply to heterogeneous demand, dynamically, programmatically, and at a speed that keeps pace with how data is actually consumed in 2026. And while the intuitive answer, or the one that ChatGPT will give you, is a marketplace, the history we have just traced tells you why that is wrong. The geometry this moment demands is a multiplexer.
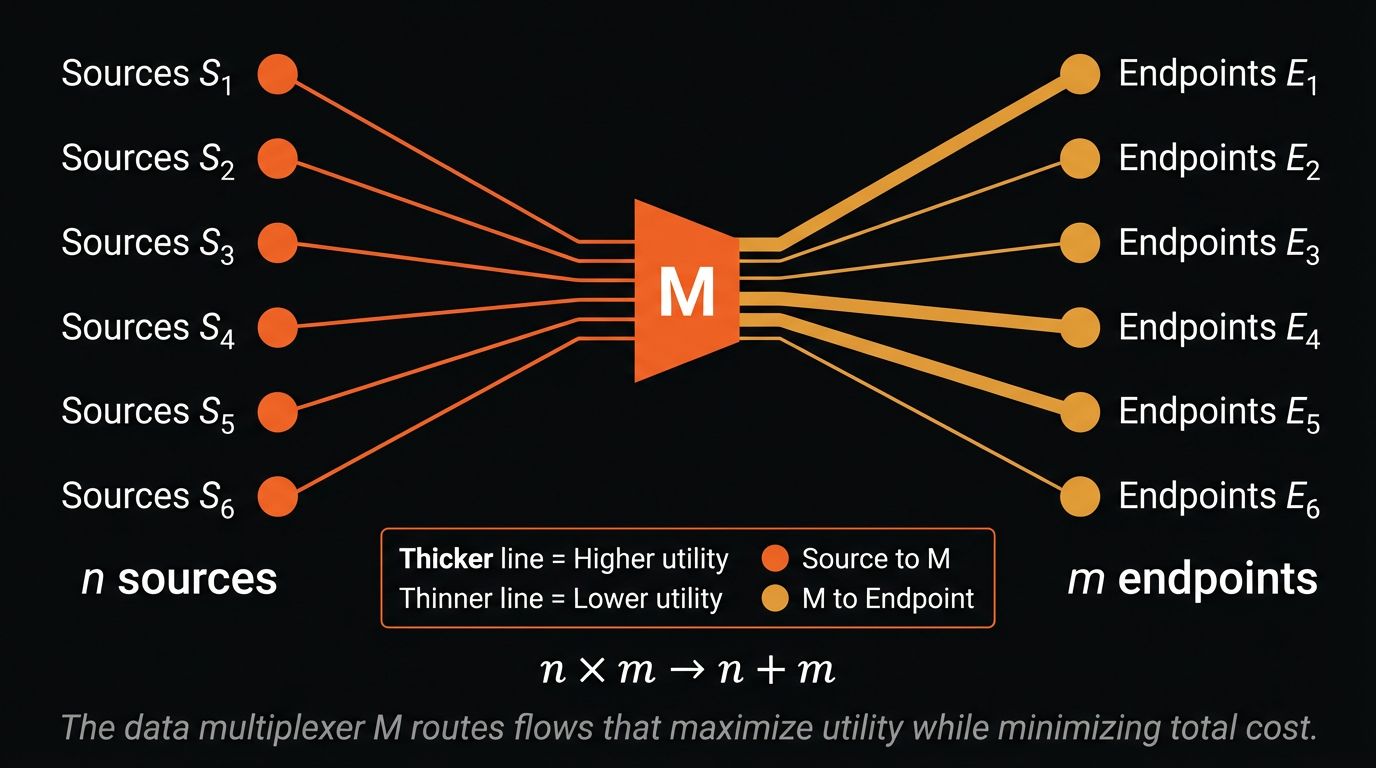
A multiplexer, as we think about it, collapses n × m bilateral connections into n + m. Instead of every buyer building a bespoke integration with every supplier, each source connects once to an adapter layer, and each endpoint connects once to that same layer. The adapter handles the work that currently consumes months and tens of thousands of dollars per deal: schema negotiation, format alignment, quality validation, licensing, delivery. Sources publish their capabilities. Endpoints describe their requirements. The multiplexer performs the matching, evaluation, and integration that a marketplace cannot.
This is not a theoretical abstraction. It is what we are building at Brickroad.
Underneath the multiplexer sits an agent-to-agent architecture. Autonomous agents on both sides of the market, representing data suppliers and data consumers, discover each other, negotiate terms, evaluate quality, settle transactions, and deliver data, all programmatically, all without the months-long procurement cycles that define the industry today. A competitive intelligence agent working on behalf of a portfolio company could describe what it needs in natural language, evaluate candidate sources against its specific task requirements, negotiate a license and price, and ingest the result. What currently takes months of procurement and tens of thousands of dollars in coordination overhead completes in minutes at marginal cost.
The implications are structural, not incremental. When transaction costs fall by orders of magnitude, the set of economically viable data transactions expands dramatically. Datasets that were never worth the coordination overhead, the long tail of niche, specialized, freshness-dependent information that sits locked inside companies who do not think of themselves as data companies, suddenly become tradeable. The viability frontier shifts outward. The long tail becomes liquid.
This is the Coasean insight applied directly: firms build internal data teams and rely on trusted intermediaries because the transaction costs of procuring data through open markets are prohibitively high. Reduce those transaction costs to near zero, and the boundary between what is efficiently sourced internally and what can be procured externally shifts dramatically. The multiplexer does not replace the market mechanism. It makes the market mechanism work for data in a way that it never has before.
And this is where Grossman-Stiglitz becomes not a warning but a design principle. The paradox tells us that transparent marketplaces destroy the incentive to gather information at the frontier. The multiplexer respects this constraint by design. Agent-to-agent transactions are bilateral, private, and non-leaking. A hedge fund's procurement activity is not visible to its competitors. A first-party data provider's customer list is not exposed to the market. The geometry preserves the opacity that frontier buyers demand while still collapsing the coordination costs that make the current market so inefficient. The infrastructure makes data liquid without making it public.
Hayek, too, finds his answer here. The most valuable data is knowledge of the particular circumstances of time and place, inherently dispersed, contextual, and resistant to centralization. A multiplexer with agents underneath does not attempt to centralize this knowledge into a catalog. It leaves it distributed and provides the routing intelligence to connect the right piece of dispersed knowledge to the right consumer at the right moment. The geometry is not hub-and-spoke. It is mesh.
To close this off: in every cycle we traced, the incumbent's greatest asset, deep integration with the prevailing geometry, became their greatest liability when the shape of information flow shifted beneath them. The courier network was useless once the wire existed. The wire service was incomplete once broadcast arrived. The broadcast feed was commoditized once the platform integrated it. The platform was overwhelmed once the data landscape fragmented beyond what any single interface could absorb.
The current cycle is no different. The fragmented alternative data landscape, combined with the emergence of agents as a fundamentally new consumer class, demands a geometry that no incumbent is positioned to build. Marketplaces cannot perform the coordination work. Platforms cannot absorb the heterogeneity. Aggregators cannot scale to the long tail. The pattern predicts that a new entrant, one unburdened by architectural commitments to the old shape, will build the infrastructure that makes data liquid.
That's why we're building the infrastructure for a liquid data economy at Brickroad. The geometry changes, but the economics never do. The entity that solves the bottleneck captures the value, and the bottleneck today is coordination. Not supply, not discovery, not access. Coordination. We believe that the multiplexer is the right geometry for this moment, and agents are the execution layer that makes it work. Brick by Brick.