DMLR: Data-Centric Machine Learning Research — Past, Present and Future
Drawing on discussions at the inaugural DMLR workshop at ICML 2023, this editorial outlines why community engagement and infrastructure are essential to creating the next generation of public datasets — and charts a collective path to sustain them for scientific, societal, and business impact.
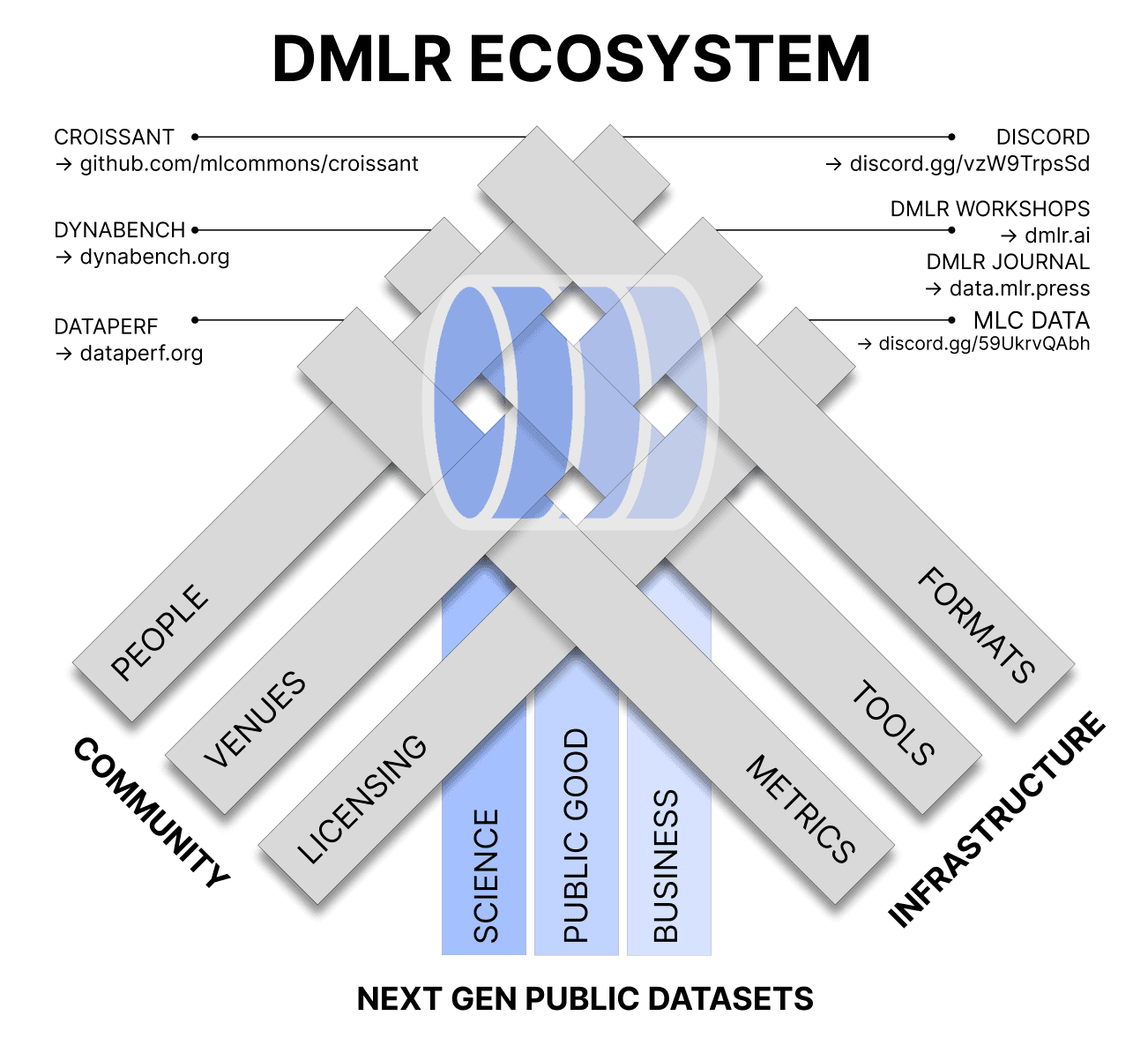
TL;DR — Machine learning has long oscillated between "design an algorithm and throw data at it" and "go back to the data to design a better algorithm." Data-Centric Machine Learning Research (DMLR) is the infrastructure, methods, and communities revolving around that second phase. Drawing on the inaugural DMLR workshop at ICML 2023 and the meetings before it, this editorial traces data-centricity through ML's past, takes stock of the present, and charts a collective path toward sustaining the next generation of public datasets. It is a community effort connected to MLCommons, the NeurIPS Datasets and Benchmarks track, the DMLR Journal, and initiatives like Croissant, DataPerf, and the Data Provenance Initiative — and an open invitation to join.
Data ambivalence in machine learning
Why state the obvious — that some ML research is "data-centric"? Hasn't ML always been about extracting models from data? In practice, the field swings between two modes: (i) design an algorithm and throw data at it, and (ii) return to the data and its representations to design a better algorithm. That oscillation produces a deep ambivalence toward data: we want algorithms to learn automatically, yet we constantly need to analyze data and models by hand to make those algorithms good. DMLR is, broadly, the infrastructure, methods, and communities revolving around phase (ii).
Past: data-centricity over time
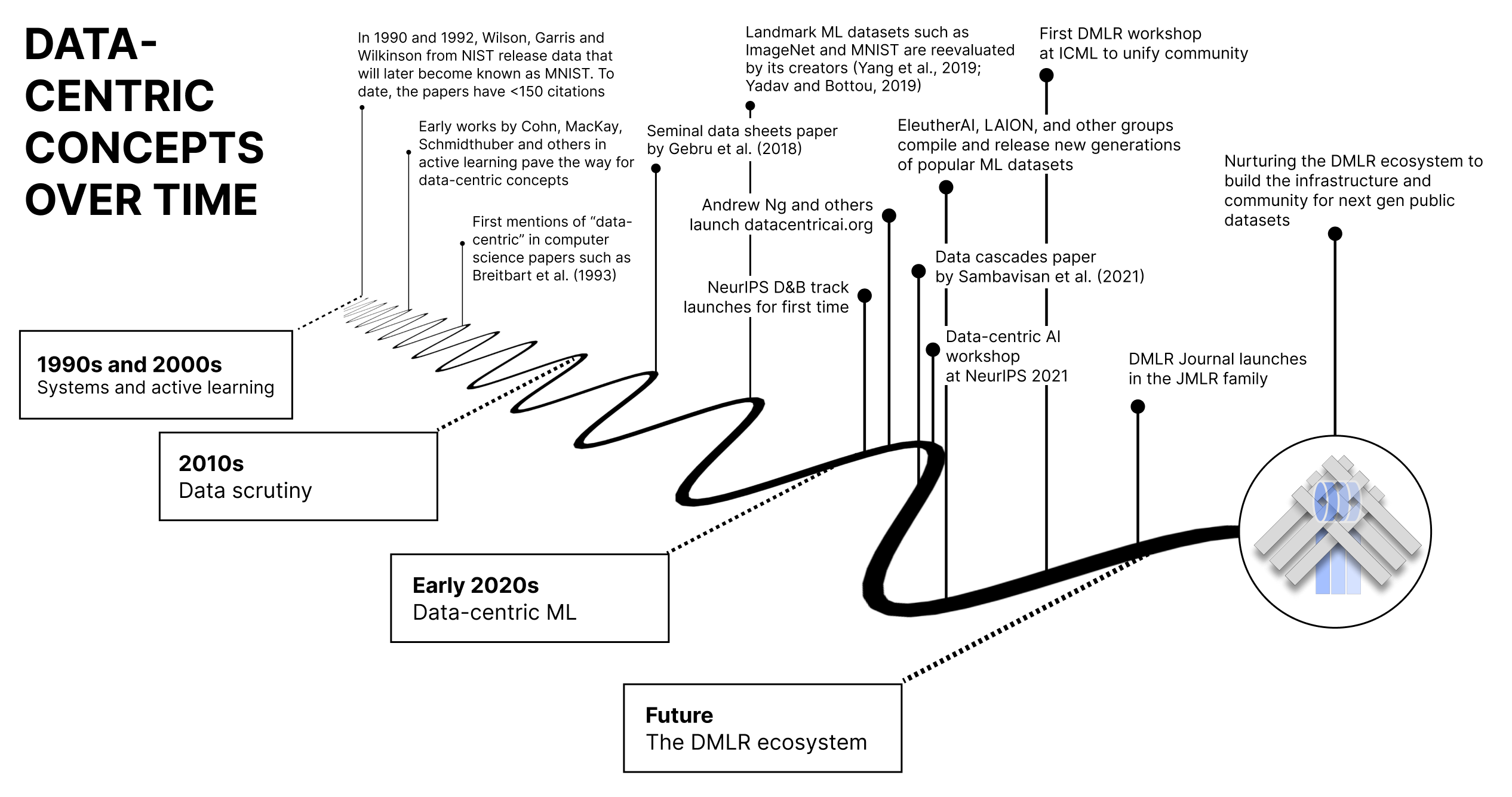
The historical record reveals how unevenly data work has been valued. The "Handwriting Sampling Forms" distributed at NIST in the early 1990s became the raw ingredients of MNIST — yet those original publications have a tiny fraction of the citations of the LeNet paper now used as a stand-in reference for the dataset. As Sambasivan et al. put it, "everyone wants to do the model work, not the data work." This isn't about drawing battle lines between "data people" and "model people"; it's about what such incentives reveal, and whether they are conducive to progress.
A few threads run through the history:
- Modality hegemony and algorithms. Leaps in algorithms tend to track the dominant data modality of the era — decision-tree families on structured tables, CNNs and AlexNet on images, RNNs/LSTMs and later transformers on text — and increasingly, methods that fuse or are agnostic to modality.
- From open to closed frontier data. Early leaps presumed open datasets like MNIST, ImageNet, and CIFAR. That is changing: for frontier models, data acquisition and preparation is such a value-generating asset that it routinely stays closed, with cooperative exceptions like LAION, Common Crawl, and EleutherAI.
- Infrastructure and curation. Data-centricity has roots in systems and database circles (visible today in venues like MLSys and the DEEM workshops), in frameworks from Torch to PyTorch and JAX, in community hubs like Kaggle, Hugging Face, and OpenML, and in curation methods from active learning onward. Newer initiatives such as Croissant tackle the "Babylonian tower" of data formats, and DataPerf benchmarks data-centric algorithms so the community can iterate on datasets, not just architectures.
Present: a field in transition
The recent DMLR workshop at ICML 2023 served as an inaugural meeting, igniting a spark for what comes next. Its accepted works and invited talks mapped out a vibrant, global community working across the data lifecycle — spanning prompt-based ML development, reality-centric AI, bias in vision data, distribution shift, data quality, and data-centric LLMs.

As large models become the norm and real-world efficacy becomes paramount, emphasis is shifting toward the entire data lifecycle — from collection through storage, transformation, and integration — alongside the societal questions that data raises. Crawled artifacts like ImageNet and LAION have introduced pressing questions of provenance, ownership, sharing, and review at scale, already playing out in copyright experiments and litigation. Alternative governance models, such as data trusts, offer frameworks to manage and govern access transparently while incentivizing the creation of new datasets and protecting sensitive information.
Future: a collective effort
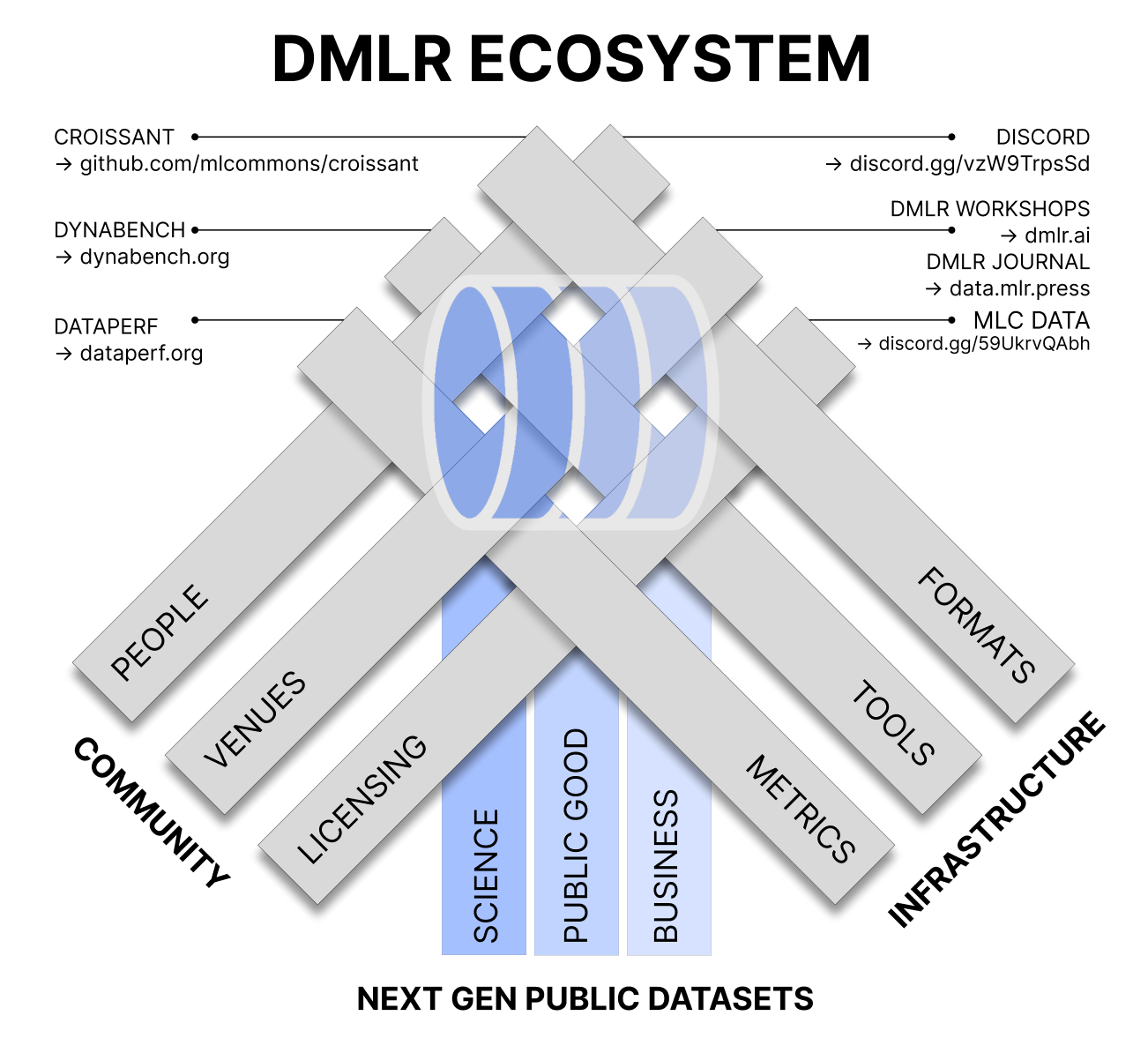
The role of the community cannot be overstated. Creating, enhancing, and maintaining public datasets is a collective effort that needs clear licensing protocols, technical standards, and a culture of shared, equitable ownership. The editorial points to concrete entry points — DMLR workshops and tracks at major conferences, the DMLR Journal, provenance and governance initiatives, informal research retreats, and open-source data-centric libraries — and to the idea of "living datasets" that emphasize the dynamic nature of data and the importance of rich, flexible metadata.
Investing in public datasets accelerates innovation, reduces legal and ethical risk, and helps address real-world challenges across healthcare, finance, agriculture, climate science, and recommender systems. The DMLR community is already expansive and ongoing — and these lines are an invitation. Whether you contribute as an open-source developer, community organizer, researcher, or reviewer, your ideas and efforts are needed to shape the data-centric future of machine learning.
Article and authors
DMLR: Data-centric Machine Learning Research — Past, Present and Future. Published in the Journal of Data-centric Machine Learning Research (DMLR). Available as an arXiv preprint (arXiv:2311.13028).
Luis Oala, Manil Maskey, Lilith Bat-Leah, Alicia Parrish, Nezihe Merve Gürel, Tzu-Sheng Kuo, Yang Liu, Rotem Dror, Danilo Brajovic, Xiaozhe Yao, Max Bartolo, William A. Gaviria Rojas, Ryan Hileman, Rainier Aliment, Michael W. Mahoney, Meg Risdal, Matthew Lease, Wojciech Samek, Debojyoti Dutta, Curtis G. Northcutt, Cody Coleman, Braden Hancock, Bernard Koch, Girmaw Abebe Tadesse, Bojan Karlaš, Ahmed Alaa, Adji Bousso Dieng, Natasha Noy, Vijay Janapa Reddi, James Zou, Praveen Paritosh, Mihaela van der Schaar, Kurt Bollacker, Lora Aroyo, Ce Zhang, Joaquin Vanschoren, Isabelle Guyon, and Peter Mattson — the DMLR Community.