Croissant: A Metadata Format for ML-Ready Datasets
Working with data is still a key friction point in machine learning. Croissant is a metadata format that creates a shared representation across ML tools, frameworks, and platforms — making datasets discoverable, portable, and interoperable. It is already supported across repositories spanning hundreds of thousands of datasets.

TL;DR — Data is a critical resource for machine learning, yet working with it remains painful: incompatible formats, no interoperability between tools, and the difficulty of discovering and combining datasets. Croissant is a metadata format that creates a shared representation of datasets across ML tools, frameworks, and platforms, making them discoverable, portable, interoperable, and "ML-ready." It is already supported by Hugging Face, Kaggle, and OpenML — together spanning hundreds of thousands of datasets — and is searchable via Google Dataset Search. Croissant was developed in the open by the MLCommons Croissant Working Group, a broad community of stakeholders from academia, industry, and research organizations.
The friction of data in ML
Recent ML advances make it clear how central data management is to progress. Yet working with data is still time-consuming and painful, thanks to a wide variety of formats, the lack of interoperability between tools, and the difficulty of discovering and combining datasets. Data's prominent role also raises questions about responsible use — licensing, privacy, fairness. We need approaches that make datasets easier to work with and easier to use responsibly.
Croissant is a metadata format designed to improve datasets' discoverability, portability, reproducibility, and interoperability. It makes datasets "ML-ready" by recording ML-specific metadata so they can be loaded directly into ML frameworks and tools. It describes a dataset's attributes, the resources it contains, and its structure and semantics — exposing a unified "view" over heterogeneous resources without requiring any change to the underlying data. That means Croissant can be added to existing datasets and adopted by repositories with minimal effort.
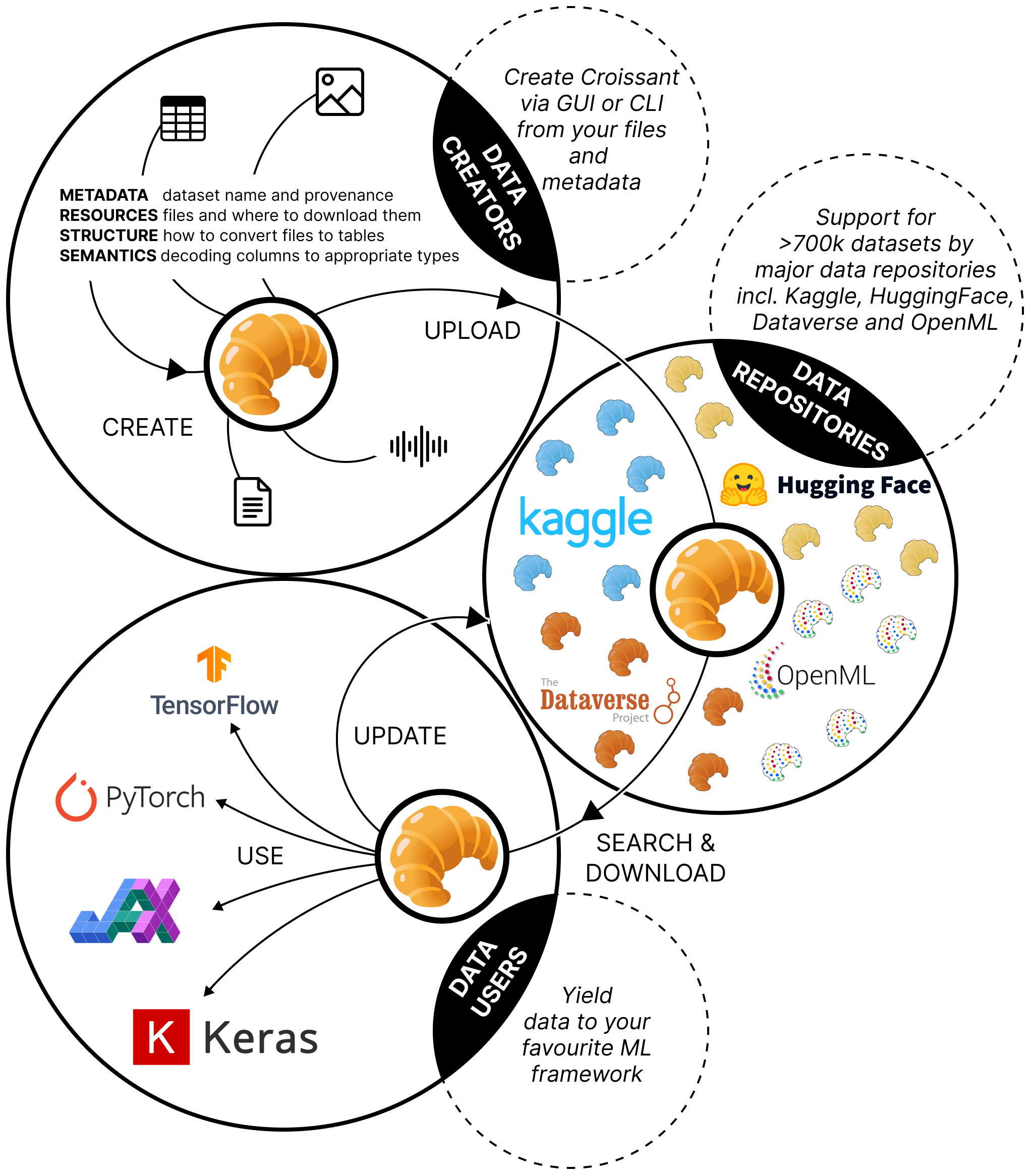
Four layers, one view
Croissant builds on Schema.org, the widely adopted vocabulary for describing things on the web, and organizes a dataset description into four layers:
- Dataset Metadata Layer — name, description, version, license, citation, and similar fields, based on
schema.org/Datasetfor interoperability with existing standards and tools. - Resource Layer — the source data, described with two primitives:
FileObjectfor individual files andFileSetfor collections of files specified by inclusion/exclusion patterns. - Structure Layer —
RecordSet, which abstracts away format heterogeneity by loading structured (CSV, JSON) and unstructured (text, audio, video) data into a common record/field representation. Fields can be nested, joined across sources, and transformed with tools like JSON Path and regular expressions. - Semantic Layer — ML-specific interpretation: dataset splits (train/test/validation), labels, and rich data types such as bounding boxes, categorical data, and segmentation masks.
For example, here is how the resource layer of the PASS dataset declares an image archive and a metadata CSV:
{
"@type": "sc:Dataset",
"name": "PASS",
"dct:conformsTo": "http://mlcommons.org/croissant/1.0",
"license": "cc-by-4.0",
"distribution": [
{
"@id": "metadata",
"@type": "cr:FileObject",
"contentUrl": "https://zenodo.org/...",
"encodingFormat": "text/csv"
},
{
"@id": "pass0",
"@type": "cr:FileObject",
"contentUrl": "https://zenodo.org/...",
"encodingFormat": "application/x-tar"
},
{
"@id": "image-files",
"@type": "cr:FileSet",
"containedIn": { "@id": "pass0" },
"includes": "*.jpg",
"encodingFormat": "image/jpeg"
}
]
}
A RecordSet then ties the images together with structured metadata — extracting the image content from the FileSet, deriving a join key from the filename via a regex, and pulling latitude/longitude from the CSV — so a loader sees one coherent table regardless of how the bytes are laid out on disk.
A responsible-AI extension
Croissant-RAI extends the format with responsible-AI metadata, building on Data Cards and Datasheets for Datasets. It was engineered iteratively around concrete use cases — documenting the data lifecycle, labeling and participatory processes, AI-safety information, fairness assessments, and regulatory compliance — making RAI metadata easier to publish, discover, and reuse.
An ecosystem, not just a spec
Croissant's value comes from being supported where practitioners already work:
- Repositories — Hugging Face Datasets, Kaggle Datasets, and OpenML together describe over 400,000 datasets in Croissant. Because Croissant extends
schema.org/Datasetand doesn't change the data layout, integration mostly meant adding fields to existing metadata. - Discovery — Google Dataset Search supports a Croissant filter, so users can restrict results to Croissant datasets across the web.
- Frameworks — the reference Python library validates, creates, and serializes Croissant and exposes an iterator that interoperates with existing loaders; TensorFlow Datasets provides a builder compatible with JAX, TensorFlow, and PyTorch.
- Editor — the Croissant Editor offers form-based editing and validation, bootstrapping resource and
RecordSetdefinitions by inferring them from uploaded data, and integrates the RAI extension.
Is the metadata any good?
To assess usability, nine practitioners with backgrounds in vocabulary engineering, dataset documentation, ML benchmarking, and responsible AI annotated ten widely used language, vision, audio, and multi-modal datasets — three annotators per dataset, thirty annotations total. The study evaluated the metadata on criteria commonly used for vocabularies, and the initial results indicate that Croissant metadata is readable, understandable, complete, yet concise.
Croissant was designed in an open, participatory way through the MLCommons Croissant Working Group, with a modular and extensible schema so that domain-specific concerns can be folded into the core format over time. (A preliminary version was presented at the DEEM 2024 workshop.)
Paper and authors
Croissant: A Metadata Format for ML-Ready Datasets. Published at the NeurIPS 2024 Datasets and Benchmarks Track. Available as an arXiv preprint (arXiv:2403.19546).
Mubashara Akhtar, Omar Benjelloun, Costanza Conforti, Luca Foschini, Joan Giner-Miguelez, Pieter Gijsbers, Sujata Goswami, Nitisha Jain, Michalis Karamousadakis, Michael Kuchnik, Satyapriya Krishna, Sylvain Lesage, Quentin Lhoest, Pierre Marcenac, Manil Maskey, Peter Mattson, Luis Oala, Hamidah Oderinwale, Pierre Ruyssen, Tim Santos, Rajat Shinde, Elena Simperl, Arjun Suresh, Goeffry Thomas, Slava Tykhonov, Joaquin Vanschoren, Susheel Varma, Jos van der Velde, Steffen Vogler, Carole-Jean Wu, and Luyao Zhang.
Developed within the MLCommons Croissant Working Group, with contributors from Google, Hugging Face, Kaggle, OpenML, and a range of academic and research institutions.