Croissant Baker: Local-First Metadata Generation for Governed ML Datasets
Croissant has become the metadata standard for ML datasets, but generating it usually means uploading data to a public platform — impossible for clinical, government, and enterprise data. Croissant Baker generates validated Croissant metadata locally, directly from a dataset directory, reaching 97-100% agreement with ground truth across domains and scaling to MIMIC-IV's 886 million rows.

TL;DR — Croissant is now the metadata standard for ML datasets, and NeurIPS requires it in every dataset-track submission. But in practice, generating Croissant means uploading your data to Hugging Face, Kaggle, or OpenML first — a non-starter for clinical data under HIPAA, government data behind procurement boundaries, or enterprise data locked by NDAs. Croissant Baker is a local-first, open-source command-line tool that generates validated Croissant metadata directly from a dataset directory, never transmitting the data. It separates deterministic, byte-traceable structural inference from optional semantic enrichment, and a typed handler registry covers the long tail of scientific formats (WFDB, DICOM, NIfTI, FHIR, OMOP, MEDS, multi-band TIFF). Evaluated on 140+ datasets, it reaches 97-100% agreement with producer-authored or standards-derived ground truth and scales to MIMIC-IV at 886M rows. A collaboration led from the MIT Laboratory for Computational Physiology with the Technical University of Munich, Helmholtz Munich, Barcelona Supercomputing Center, Harvard, Bayer, Eindhoven University of Technology, and others, within the MLCommons Croissant ecosystem.
The gap: governed data can't reach the metadata standard
Croissant provides a structured, JSON-LD-based format that makes datasets discoverable, automatically ingestible, and reproducible across ML platforms. Adoption has accelerated to the point that NeurIPS now requires Croissant metadata in every submission to its dataset tracks.
But the current authoring pipeline silently assumes one thing: that you can upload your data. Hugging Face, Kaggle, and OpenML all generate metadata only after a dataset has been transmitted to a public platform. That path is infeasible for exactly the data ecosystems where ML increasingly matters — clinical data governed by HIPAA and data-use agreements, government data behind security boundaries, and enterprise data locked by NDAs.
Even when upload is allowed, platform-side generation can't fully close the gap. Turning raw files into valid Croissant requires a recovery layer between bytes and dataset structure that no generic file walk reconstructs:
- WFDB records couple
.heaheaders with one or more.datsignal files. - FHIR requires content-aware dispatch between Bundle and NDJSON serializations.
- Parquet tables may be partitioned across directories.
- DICOM and NIfTI encode acquisition metadata in headers that must be parsed without materializing pixel or voxel payloads.
- Multi-band scientific TIFFs (e.g., 12-band Sentinel-2) carry band structure that ordinary image abstractions collapse.
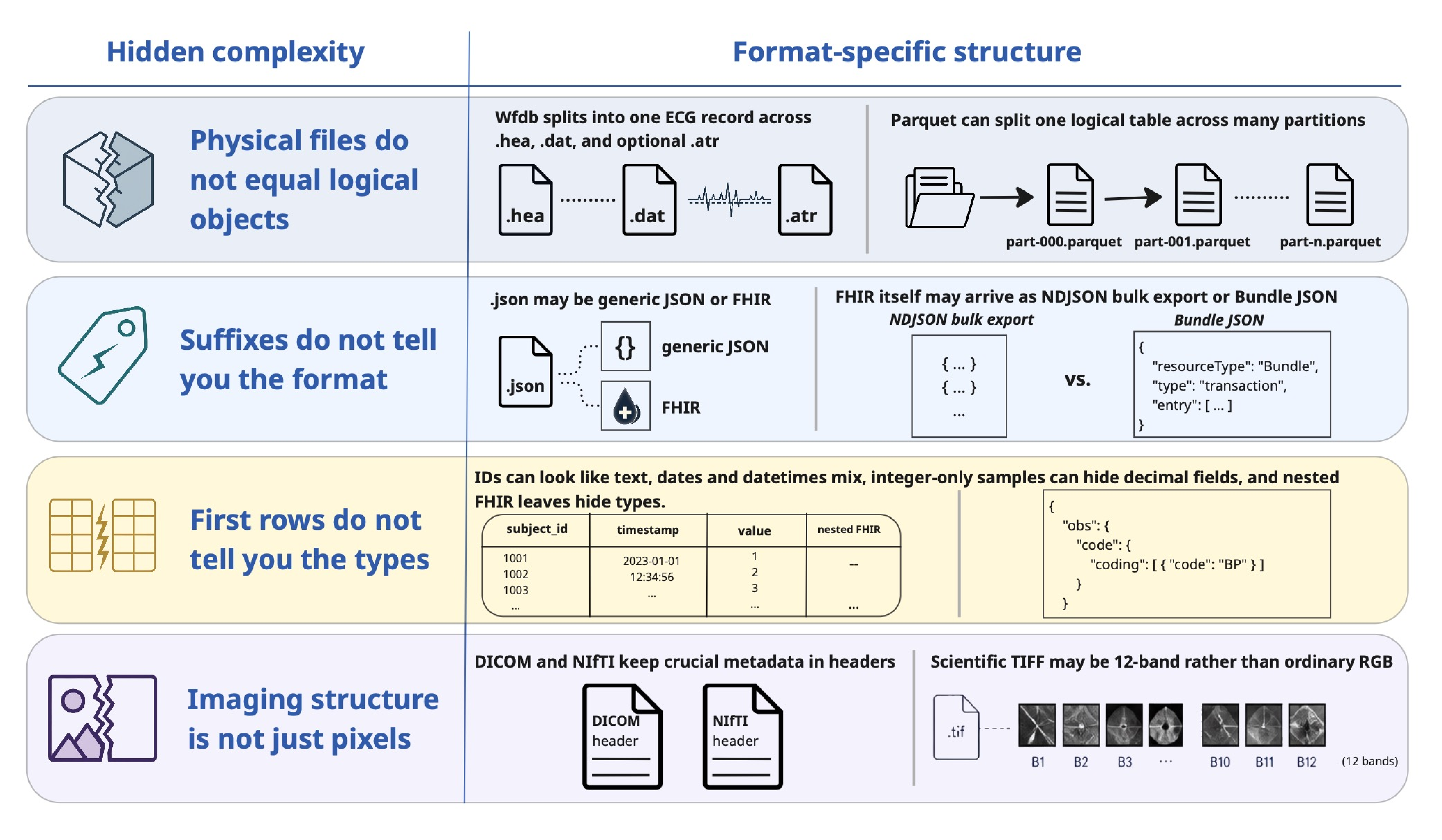
Without this knowledge, platform generators misclassify datetimes as dates, integer IDs as text, or emit empty schemas for waveform and multi-band inputs.
The design: deterministic structure, optional enrichment
Croissant Baker closes the gap with two architectural commitments.
1. A clean split between structure and semantics. Deterministic structural inference is file-derived, byte-traceable, and reproducible by construction. Semantic enrichment (descriptions, citations, intended use) is supplied separately via the CLI or an agent, under explicit human review. Every value in the output document is auditable to either source-file bytes or an explicit input — and the structural core composes with agent-based authoring rather than competing with it.
2. A typed handler protocol for the long tail. New formats register once with a dispatch table without touching the inference core, each exercised by regression tests on fixture datasets. Built-in handlers span tabular, columnar, JSON, waveform, image, and biomedical formats including WFDB, DICOM, NIfTI, FHIR, OMOP, and MEDS.
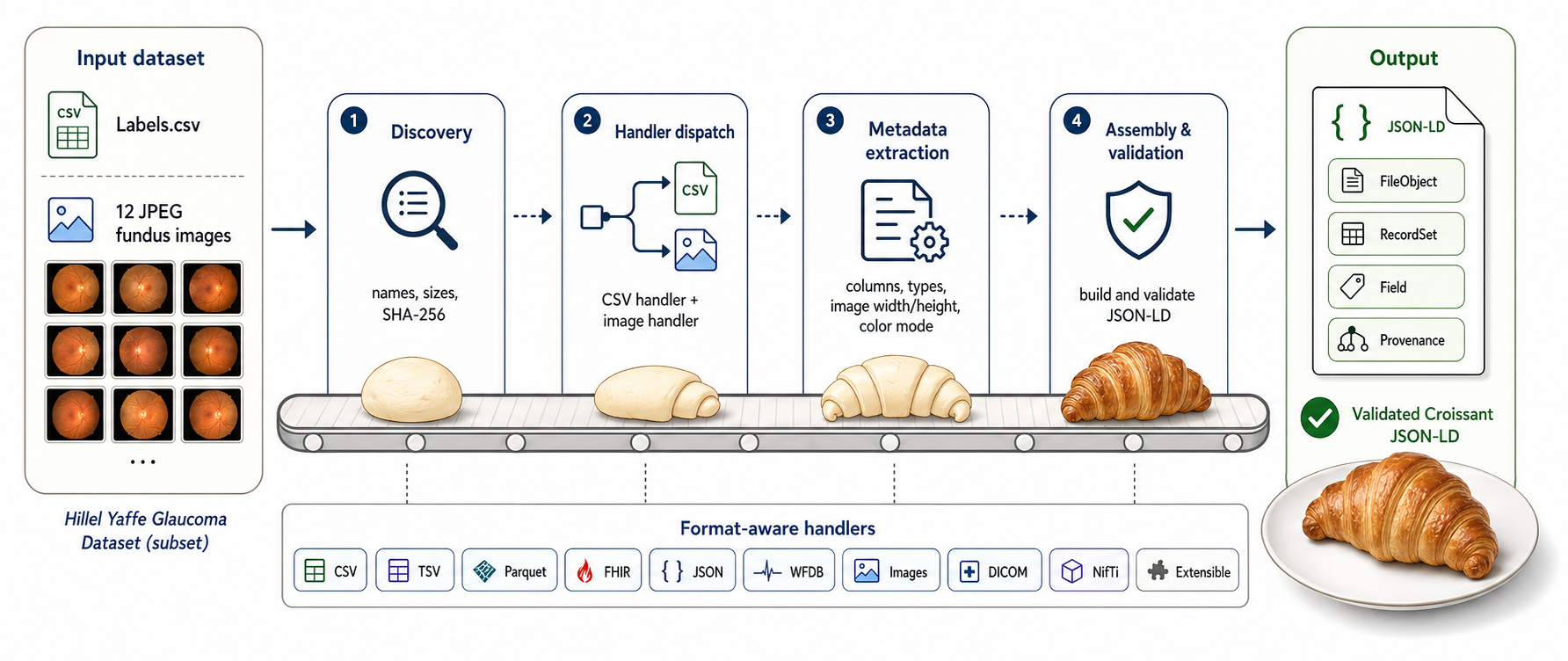
This separation is why direct LLM-only generation falls short: outputs aren't deterministically derivable from source files (a reproducibility blocker for governed data), context windows can't hold institutional-scale repositories, and frontier models don't natively parse binary DICOM, NIfTI, TIFF, or WFDB headers.
The results: high agreement, real scale
Croissant Baker was evaluated across development, scalability, and five held-out splits, emphasizing biomedical and adjacent scientific data because it combines the two pressures that make authoring hard: strict governance that rules out upload, and format diversity that rules out one-size-fits-all parsing.
- Local generation succeeds across nine heterogeneous datasets spanning tabular, columnar, waveform, and image modalities — 768 files represented as
FileObjectentries with 599 logicalRecordSetobjects, all passingmlcroissantvalidation without modification. - Scale: MIMIC-IV at full size (9.92 GB) processes in 13.3 seconds; MIMIC-IV MEDS (366 Parquet files, 3.67 GB) in 32.2 seconds — demonstrating institutional-scale viability at 886 million rows and 374 Parquet files.
- Held-out agreement against ground truth:
- 97.9% semantic type agreement on a deterministic seeded draw of 25 datasets across the 11 OpenReview primary-area buckets of the NeurIPS 2025 Datasets & Benchmarks track.
- 97.4% on 55 Open Targets datasets with producer-authored Croissant metadata (all 55 RecordSet names and all 819 field names recovered).
- 97.8% on a SMART Health IT FHIR release resolved against US Core and HL7 R4.
- 100% strict tag-ID agreement against the DICOM PS3.6 dictionary across six vendor modules.
- 51 OpenNeuro BIDS datasets baked without a single failure.
Notably, most of the residual disagreements aren't errors: they occur when human-authored metadata assigns sc:Float to integer-valued columns, whereas Baker infers the more precise integer type directly from the Parquet schema.
Why it matters downstream
Once a dataset carries valid Croissant, the mlcroissant API loads each document and iterates over RecordSets without dataset-specific ingestion code. Cross-site schema comparison — an OMOP-to-MEDS or two-site MIMIC-IV consistency check that used to require custom parsers per institution — collapses to a single load and a set diff. The same documents act as packaging contracts: controlled perturbations like a removed file, a renamed waveform component, or a changed column name are caught by validation before downstream analysis. And metadata-only export supports discoverability and submission compliance for controlled-access data without moving patient-level content.
By bringing governed and long-tail data into ML metadata standards, Croissant Baker lets data that previously couldn't participate meet emerging publication and review requirements on equal footing with platform-hosted data.
The tool is open source — project page, code on GitHub.
Paper and authors
Croissant Baker: Metadata Generation for Discoverable, Governable, and Reusable ML Datasets. Available as an arXiv preprint (arXiv:2605.15079).
Rafi Al Attrach, Rajna Fani, Sebastian Lobentanzer, Joan Giner-Miguelez, Debanshu Das, Varuni H. K., Nobin Sarwar, Rajat Ghosh, Anwai Archit, Surbhi Motghare, Christina Conrad Parry, Luis Oala, Lara Grosso, Joaquin Vanschoren, Steffen Vogler, Sujata Goswami, Eric S. Rosenthal, Marzyeh Ghassemi, Matthew McDermott, and Tom Pollard.
Affiliations: Technical University of Munich, Massachusetts Institute of Technology, Helmholtz Munich, Barcelona Supercomputing Center, Google, Couchbase, University of Maryland Baltimore County, Nutanix, Georg-August-University Göttingen, Salesforce, Sage Bionetworks, Dotphoton, Harvard University, Eindhoven University of Technology, Bayer AG, Massachusetts General Hospital, and Columbia University.